import RealTimeAgg from 'versionContent/_partials/_real-time-aggregates.mdx';
In modern applications, data usually grows very quickly. This means that aggregating it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your data into minutes or hours instead. For example, if an IoT device takes temperature readings every second, you might want to find the average temperature for each hour. Every time you run this query, the database needs to scan the entire table and recalculate the average. $TIMESCALE_DB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
Continuous aggregates in $TIMESCALE_DB are a kind of hypertable that is refreshed automatically in the background as new data is added, or old data is modified. Changes to your dataset are tracked, and the hypertable behind the continuous aggregate is automatically updated in the background.
Continuous aggregates have a much lower maintenance burden than regular $PG materialized views, because the whole view is not created from scratch on each refresh. This means that you can get on with working your data instead of maintaining your database.
Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the columnstore, or tiered to object storage. You can even create continuous aggregates on top of your continuous aggregates, for an even more fine-tuned aggregation.
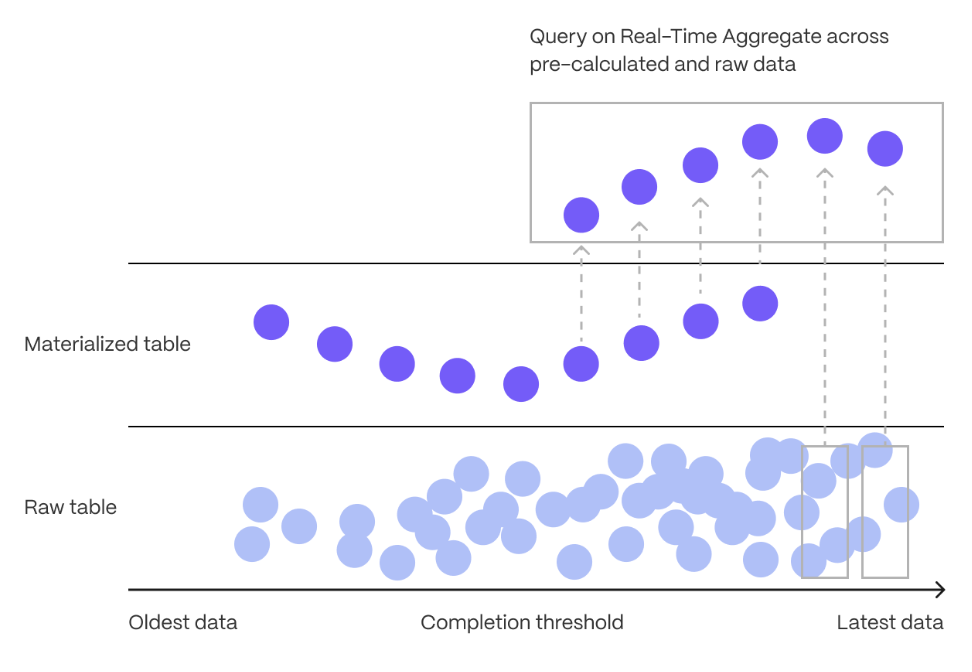
Real-time aggregation enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query.