diff --git a/.helper-scripts/llms/generate_llms_full.py b/.helper-scripts/llms/generate_llms_full.py
index 37b9a8b26e..1d0336eac9 100644
--- a/.helper-scripts/llms/generate_llms_full.py
+++ b/.helper-scripts/llms/generate_llms_full.py
@@ -712,7 +712,7 @@ def process_imports(self, content: str, current_file_path: Path) -> str:
print(f"Replaced {component_name} using default path: {default_path}")
# Remove or replace components that don't have clear partials
- orphaned_components = ['Installation', 'Skip', 'OldCreateHypertable', 'PolicyVisualizerDownsampling', 'APIReference', 'Since2180']
+ orphaned_components = ['Installation', 'Skip', 'OldCreateHypertable', 'CreateHypertablePolicyNote', 'PolicyVisualizerDownsampling', 'APIReference', 'Since2180']
for component_name in orphaned_components:
# Handle both normal and spaced component tags
component_tags = [
diff --git a/_partials/_create-hypertable-blockchain.md b/_partials/_create-hypertable-blockchain.md
index bfd672de63..63f0b3c438 100644
--- a/_partials/_create-hypertable-blockchain.md
+++ b/_partials/_create-hypertable-blockchain.md
@@ -1,4 +1,4 @@
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intro.mdx";
## Optimize time-series data using hypertables
@@ -31,13 +31,12 @@ import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intr
details JSONB
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.segmentby='block_id',
tsdb.orderby='time DESC'
);
```
-
+
1. Create an index on the `hash` column to make queries for individual
transactions faster:
diff --git a/_partials/_create-hypertable-columnstore-policy-note.md b/_partials/_create-hypertable-columnstore-policy-note.md
new file mode 100644
index 0000000000..c31a73ade6
--- /dev/null
+++ b/_partials/_create-hypertable-columnstore-policy-note.md
@@ -0,0 +1,18 @@
+When you create a $HYPERTABLE using [CREATE TABLE ... WITH ...][hypertable-create-table], the default partitioning
+column is automatically the first column with a timestamp data type. Also, $TIMESCALE_DB creates a
+[columnstore policy][add_columnstore_policy] that automatically converts your data to the $COLUMNSTORE, after an interval equal to the value of the [chunk_interval][create_table_arguments], defined through `compress_after` in the policy. This columnar format enables fast scanning and
+aggregation, optimizing performance for analytical workloads while also saving significant storage space. In the
+$COLUMNSTORE conversion, $HYPERTABLE chunks are compressed by up to 98%, and organized for efficient, large-scale queries.
+
+You can customize this policy later using [alter_job][alter_job_samples]. However, to change `after` or
+`created_before`, the compression settings, or the $HYPERTABLE the policy is acting on, you must
+[remove the columnstore policy][remove_columnstore_policy] and [add a new one][add_columnstore_policy].
+
+You can also manually [convert chunks][convert_to_columnstore] in a $HYPERTABLE to the $COLUMNSTORE.
+
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
+[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
+[create_table_arguments]: /api/:currentVersion:/hypertable/create_table/#arguments
+[alter_job_samples]: /api/:currentVersion:/jobs-automation/alter_job/#samples
+[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
+[hypertable-create-table]: /api/:currentVersion:/hypertable/create_table/
\ No newline at end of file
diff --git a/_partials/_create-hypertable-energy.md b/_partials/_create-hypertable-energy.md
index 7ff1cf0f4b..41e454eb9d 100644
--- a/_partials/_create-hypertable-energy.md
+++ b/_partials/_create-hypertable-energy.md
@@ -1,4 +1,4 @@
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intro.mdx";
## Optimize time-series data in hypertables
@@ -15,12 +15,11 @@ import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intr
type_id integer not null,
value double precision not null
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
diff --git a/_partials/_create-hypertable-nyctaxis.md b/_partials/_create-hypertable-nyctaxis.md
index 585192ea92..77324274a3 100644
--- a/_partials/_create-hypertable-nyctaxis.md
+++ b/_partials/_create-hypertable-nyctaxis.md
@@ -1,4 +1,4 @@
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
## Optimize time-series data in hypertables
@@ -15,7 +15,6 @@ same way. You use regular $PG tables for relational data.
1. **Create a $HYPERTABLE to store the taxi trip data**
-
```sql
CREATE TABLE "rides"(
vendor_id TEXT,
@@ -38,11 +37,10 @@ same way. You use regular $PG tables for relational data.
total_amount NUMERIC
) WITH (
tsdb.hypertable,
- tsdb.partition_column='pickup_datetime',
tsdb.create_default_indexes=false
);
```
-
+
1. **Add another dimension to partition your $HYPERTABLE more efficiently**
diff --git a/_partials/_create-hypertable-twelvedata-crypto.md b/_partials/_create-hypertable-twelvedata-crypto.md
index f5bc74f7d0..722aa68dfe 100644
--- a/_partials/_create-hypertable-twelvedata-crypto.md
+++ b/_partials/_create-hypertable-twelvedata-crypto.md
@@ -1,5 +1,5 @@
import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intro.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
## Optimize time-series data in a hypertable
@@ -25,12 +25,11 @@ import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypert
day_volume NUMERIC
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.segmentby='symbol',
tsdb.orderby='time DESC'
);
```
-
+
diff --git a/_partials/_create-hypertable-twelvedata-stocks.md b/_partials/_create-hypertable-twelvedata-stocks.md
index 70a431f1ae..1a597397e5 100644
--- a/_partials/_create-hypertable-twelvedata-stocks.md
+++ b/_partials/_create-hypertable-twelvedata-stocks.md
@@ -1,5 +1,5 @@
import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intro.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
## Optimize time-series data in hypertables
@@ -20,11 +20,10 @@ import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypert
price DOUBLE PRECISION NULL,
day_volume INT NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
1. **Create an index to support efficient queries**
diff --git a/_partials/_create-hypertable.md b/_partials/_create-hypertable.md
index 56ed0c630a..46ab0ba998 100644
--- a/_partials/_create-hypertable.md
+++ b/_partials/_create-hypertable.md
@@ -1,5 +1,5 @@
import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intro.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
@@ -22,11 +22,10 @@ To create a hypertable:
price DOUBLE PRECISION NULL,
day_volume INT NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
You see the result immediately:
diff --git a/_partials/_dimensions_info.md b/_partials/_dimensions_info.md
index 742d28ea66..9a932b6530 100644
--- a/_partials/_dimensions_info.md
+++ b/_partials/_dimensions_info.md
@@ -1,4 +1,4 @@
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
### Dimension info
@@ -46,12 +46,11 @@ Create a by-range dimension builder. You can partition `by_range` on it's own.
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
This is the default partition, you do not need to add it explicitly.
@@ -152,8 +151,7 @@ CREATE TABLE conditions (
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time',
+ tsdb.hypertable
tsdb.chunk_interval='1 day'
);
diff --git a/_partials/_hypercore-intro-short.md b/_partials/_hypercore-intro-short.md
index a43eba377f..19d6dc9408 100644
--- a/_partials/_hypercore-intro-short.md
+++ b/_partials/_hypercore-intro-short.md
@@ -6,6 +6,8 @@ transactional capabilities.
$HYPERCORE_CAP dynamically stores data in the most efficient format for its lifecycle:
+
+
* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the $ROWSTORE,
ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
writethrough for inserts and updates to columnar storage.
diff --git a/_partials/_hypercore_create_hypertable_columnstore_policy.md b/_partials/_hypercore_create_hypertable_columnstore_policy.md
new file mode 100644
index 0000000000..018d4c48dd
--- /dev/null
+++ b/_partials/_hypercore_create_hypertable_columnstore_policy.md
@@ -0,0 +1,64 @@
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
+
+1. **Enable $COLUMNSTORE on a $HYPERTABLE**
+
+ For [efficient queries][secondary-indexes], remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+ * **$HYPERTABLE_CAPs**:
+
+ [Use `CREATE TABLE` for a $HYPERTABLE][hypertable-create-table]
+
+ ```sql
+ CREATE TABLE crypto_ticks (
+ "time" TIMESTAMPTZ,
+ symbol TEXT,
+ price DOUBLE PRECISION,
+ day_volume NUMERIC
+ ) WITH (
+ timescaledb.hypertable,
+ timescaledb.segmentby='symbol',
+ timescaledb.orderby='time DESC'
+ );
+ ```
+
+
+ * **$CAGG_CAPs**
+ 1. [Use `ALTER MATERIALIZED VIEW` for a $CAGG][compression_continuous-aggregate]:
+ ```sql
+ ALTER MATERIALIZED VIEW assets_candlestick_daily set (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'symbol');
+ ```
+ Before you say `huh`, a $CAGG is a specialized $HYPERTABLE.
+
+ 1. Add a policy to convert $CHUNKs to the $COLUMNSTORE at a specific time interval:
+
+ Create a [columnstore_policy][add_columnstore_policy] that automatically converts $CHUNKs in a $HYPERTABLE to
+ the $COLUMNSTORE at a specific time interval. For example:
+ ``` sql
+ CALL add_columnstore_policy('assets_candlestick_daily', after => INTERVAL '1d');
+ ```
+
+ $TIMESCALE_DB is optimized for fast updates on compressed data in the $COLUMNSTORE. To modify data in the
+ $COLUMNSTORE, use standard SQL.
+
+
+[job]: /api/:currentVersion:/actions/add_job/
+[alter_table_hypercore]: /api/:currentVersion:/hypercore/alter_table/
+[compression_continuous-aggregate]: /api/:currentVersion:/continuous-aggregates/alter_materialized_view/
+[convert_to_rowstore]: /api/:currentVersion:/hypercore/convert_to_rowstore/
+[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
+[informational-views]: /api/:currentVersion:/informational-views/jobs/
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
+[hypercore_workflow]: /api/:currentVersion:/hypercore/#hypercore-workflow
+[alter_job]: /api/:currentVersion:/actions/alter_job/
+[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[services-portal]: https://console.cloud.timescale.com/dashboard/services
+[connect-using-psql]: /integrations/:currentVersion:/psql/#connect-to-your-service
+[insert]: /use-timescale/:currentVersion:/write-data/insert/
+[hypertables-section]: /use-timescale/:currentVersion:/hypertables/
+[hypertable-create-table]: /api/:currentVersion:/hypertable/create_table/
+[hypercore]: /use-timescale/:currentVersion:/hypercore/
+[secondary-indexes]: /use-timescale/:currentVersion:/hypercore/secondary-indexes/
diff --git a/_partials/_hypercore_policy_workflow.md b/_partials/_hypercore_policy_workflow.md
index 25cba9c4b7..b7ce2f6835 100644
--- a/_partials/_hypercore_policy_workflow.md
+++ b/_partials/_hypercore_policy_workflow.md
@@ -1,4 +1,4 @@
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertableProcedure from "versionContent/_partials/_hypercore_create_hypertable_columnstore_policy.mdx";
@@ -6,46 +6,7 @@ import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypert
In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your $SERVICE_SHORT using [psql][connect-using-psql].
-1. **Enable $COLUMNSTORE on a $HYPERTABLE**
-
- Create a [$HYPERTABLE][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
- For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
- use most often to filter your data. For example:
-
- * [Use `CREATE TABLE` for a $HYPERTABLE][hypertable-create-table]
-
- ```sql
- CREATE TABLE crypto_ticks (
- "time" TIMESTAMPTZ,
- symbol TEXT,
- price DOUBLE PRECISION,
- day_volume NUMERIC
- ) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time',
- tsdb.segmentby='symbol',
- tsdb.orderby='time DESC'
- );
- ```
-
-
- * [Use `ALTER MATERIALIZED VIEW` for a $CAGG][compression_continuous-aggregate]
- ```sql
- ALTER MATERIALIZED VIEW assets_candlestick_daily set (
- timescaledb.enable_columnstore = true,
- timescaledb.segmentby = 'symbol' );
- ```
- Before you say `huh`, a $CAGG is a specialized $HYPERTABLE.
-
-1. **Add a policy to convert $CHUNKs to the $COLUMNSTORE at a specific time interval**
-
- Create a [columnstore_policy][add_columnstore_policy] that automatically converts $CHUNKs in a $HYPERTABLE to the $COLUMNSTORE at a specific time interval. For example, convert yesterday's crypto trading data to the $COLUMNSTORE:
- ``` sql
- CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '1d');
- ```
-
- $TIMESCALE_DB is optimized for fast updates on compressed data in the $COLUMNSTORE. To modify data in the
- $COLUMNSTORE, use standard SQL.
+
1. **Check the $COLUMNSTORE policy**
diff --git a/_partials/_import-data-iot.md b/_partials/_import-data-iot.md
index e0daabaa8c..314265b44d 100644
--- a/_partials/_import-data-iot.md
+++ b/_partials/_import-data-iot.md
@@ -1,4 +1,4 @@
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intro.mdx";
@@ -38,12 +38,11 @@ import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intr
value double precision not null
) WITH (
tsdb.hypertable,
- tsdb.partition_column='created',
tsdb.segmentby = 'type_id',
tsdb.orderby = 'created DESC'
);
```
-
+
1. Upload the dataset to your $SERVICE_SHORT
```sql
diff --git a/_partials/_import-data-nyc-taxis.md b/_partials/_import-data-nyc-taxis.md
index 1411b6a434..abf586643a 100644
--- a/_partials/_import-data-nyc-taxis.md
+++ b/_partials/_import-data-nyc-taxis.md
@@ -1,4 +1,4 @@
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intro.mdx";
@@ -53,13 +53,12 @@ import HypertableIntro from "versionContent/_partials/_tutorials_hypertable_intr
total_amount NUMERIC
) WITH (
tsdb.hypertable,
- tsdb.partition_column='pickup_datetime',
tsdb.create_default_indexes=false,
tsdb.segmentby='vendor_id',
tsdb.orderby='pickup_datetime DESC'
);
```
-
+
1. Add another dimension to partition your $HYPERTABLE more efficiently:
```sql
diff --git a/_partials/_old-api-create-hypertable.md b/_partials/_old-api-create-hypertable.md
index b9b5b18b07..7d095acd62 100644
--- a/_partials/_old-api-create-hypertable.md
+++ b/_partials/_old-api-create-hypertable.md
@@ -1,8 +1,23 @@
-If you are self-hosting $TIMESCALE_DB v2.19.3 and below, create a [$PG relational table][pg-create-table],
+For $TIMESCALE_DB [v2.23.0][tsdb-release-2-23-0] and higher, the table is automatically partitioned on the first column
+in the table with a timestamp data type. If multiple columns are suitable candidates as a partitioning column,
+$TIMESCALE_DB throws an error and asks for an explicit definition. For earlier versions, set `partition_column` to a
+time column.
+
+If you are self-hosting $TIMESCALE_DB [v2.20.0][tsdb-release-2-23-0] to [v2.22.1][tsdb-release-2-23-0], to convert your
+data to the $COLUMNSTORE after a specific time interval, you have to call [add_columnstore_policy] after you call
+[CREATE TABLE][hypertable-create-table]
+
+If you are self-hosting $TIMESCALE_DB [v2.19.3][tsdb-release-2-19-3] and below, create a [$PG relational table][pg-create-table],
then convert it using [create_hypertable][create_hypertable]. You then enable $HYPERCORE with a call
to [ALTER TABLE][alter_table_hypercore].
-
[pg-create-table]: https://www.postgresql.org/docs/current/sql-createtable.html
[create_hypertable]: /api/:currentVersion:/hypertable/create_hypertable/
[alter_table_hypercore]: /api/:currentVersion:/hypercore/alter_table/
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
+[hypertable-create-table]: /api/:currentVersion:/hypertable/create_table/
+[chunk_interval]: /api/:currentVersion:/hypertable/set_chunk_time_interval/
+[tsdb-release-2-23-0]: https://github.com/timescale/timescaledb/releases/tag/2.23.0
+[tsdb-release-2-20-0]: https://github.com/timescale/timescaledb/releases/tag/2.20.0
+[tsdb-release-2-22-1]: https://github.com/timescale/timescaledb/releases/tag/2.22.1
+[tsdb-release-2-19-3]: https://github.com/timescale/timescaledb/releases/tag/2.19.3
\ No newline at end of file
diff --git a/api/hypercore/add_columnstore_policy.md b/api/hypercore/add_columnstore_policy.md
index a460736465..254f6e3327 100644
--- a/api/hypercore/add_columnstore_policy.md
+++ b/api/hypercore/add_columnstore_policy.md
@@ -12,26 +12,33 @@ api:
import Since2180 from "versionContent/_partials/_since_2_18_0.mdx";
import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# add_columnstore_policy()
Create a [job][job] that automatically moves chunks in a hypertable to the $COLUMNSTORE after a
specific time interval.
-You enable the $COLUMNSTORE a hypertable or continuous aggregate before you create a $COLUMNSTORE policy.
-You do this by calling `CREATE TABLE` for hypertables and `ALTER MATERIALIZED VIEW` for continuous aggregates. When
-$COLUMNSTORE is enabled, [bloom filters][bloom-filters] are enabled by default, and every new chunk has a bloom index.
-If you converted chunks to $COLUMNSTORE using $TIMESCALE_DB v2.19.3 or below, to enable bloom filters on that data you have
-to convert those chunks to the $ROWSTORE, then convert them back to the $COLUMNSTORE.
+- **$CAGG_CAPs**:
+
+ You first call `ALTER MATERIALIZED VIEW` to enable the $COLUMNSTORE on a $CAGG, then create the job that converts
+ your data to the $COLUMNSTORE with a call to `add_columnstore_policy`.
+
+- **$HYPERTABLE_CAPs**:
-Bloom indexes are not retrofitted, meaning that the existing chunks need to be fully recompressed to have the bloom
-indexes present. Please check out the PR description for more in-depth explanations of how bloom filters in
-TimescaleDB work.
+
-To view the policies that you set or the policies that already exist,
-see [informational views][informational-views], to remove a policy, see [remove_columnstore_policy][remove_columnstore_policy].
+When $COLUMNSTORE is enabled, [bloom filters][bloom-filters] are enabled by default, and every new chunk has a bloom index.
+Bloom indexes are not retrofitted, existing chunks need to be fully recompressed to have the bloom indexes present. If
+you converted chunks to $COLUMNSTORE using $TIMESCALE_DB [v2.19.3](tsdb-release-2-19-3) or below, to enable bloom filters on that data you have
+to convert those chunks to the $ROWSTORE, then convert them back to the $COLUMNSTORE.
+
+To view the policies that you set or the policies that already exist, see [informational views][informational-views].
-A $COLUMNSTORE policy is applied on a per-chunk basis. If you remove an existing policy and then add a new one, the new policy applies only to the chunks that have not yet been converted to $COLUMNSTORE. The existing chunks in the $COLUMNSTORE remain unchanged. This means that chunks with different $COLUMNSTORE settings can co-exist in the same $HYPERTABLE.
+A $COLUMNSTORE policy is applied on a per-chunk basis. If you remove an existing policy and then add a new one, the new
+policy applies only to the chunks that have not yet been converted to $COLUMNSTORE. The existing chunks in the
+$COLUMNSTORE remain unchanged. This means that chunks with different $COLUMNSTORE settings can co-exist in the same
+$HYPERTABLE.
@@ -39,15 +46,18 @@ A $COLUMNSTORE policy is applied on a per-chunk basis. If you remove an existing
To create a $COLUMNSTORE job:
-
-
-1. **Enable $COLUMNSTORE**
+- **Enable $COLUMNSTORE**
- Create a [$HYPERTABLE][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
- For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
- use most often to filter your data. For example:
+ For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+ use most often to filter your data.
+ * [Use `ALTER MATERIALIZED VIEW` for a continuous aggregate][compression_continuous-aggregate]
+ ```sql
+ ALTER MATERIALIZED VIEW assets_candlestick_daily SET (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'symbol');
+ ```
- * [Use `CREATE TABLE` for a $HYPERTABLE][hypertable-create-table]
+ * [Use `CREATE TABLE` for a $HYPERTABLE][hypertable-create-table]. The columnstore policy is created automatically.
```sql
CREATE TABLE crypto_ticks (
@@ -57,21 +67,13 @@ To create a $COLUMNSTORE job:
day_volume NUMERIC
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.segmentby='symbol',
tsdb.orderby='time DESC'
);
```
- * [Use `ALTER MATERIALIZED VIEW` for a continuous aggregate][compression_continuous-aggregate]
- ```sql
- ALTER MATERIALIZED VIEW assets_candlestick_daily set (
- timescaledb.enable_columnstore = true,
- timescaledb.segmentby = 'symbol' );
- ```
-
-1. **Add a policy to move chunks to the $COLUMNSTORE at a specific time interval**
+- **Add a policy to move chunks to the $COLUMNSTORE at a specific time interval**
For example:
@@ -114,7 +116,7 @@ To create a $COLUMNSTORE job:
```
-1. **View the policies that you set or the policies that already exist**
+- **View the policies that you set or the policies that already exist**
``` sql
SELECT * FROM timescaledb_information.jobs
@@ -122,7 +124,7 @@ To create a $COLUMNSTORE job:
```
See [timescaledb_information.jobs][informational-views].
-
+
## Arguments
@@ -159,3 +161,7 @@ Calls to `add_columnstore_policy` require either `after` or `created_before`, bu
[hypercore]: /use-timescale/:currentVersion:/hypercore/
[secondary-indexes]: /use-timescale/:currentVersion:/hypercore/secondary-indexes/
[bloom-filters]: https://en.wikipedia.org/wiki/Bloom_filter
+[create_table_arguments]: /api/:currentVersion:/hypertable/create_table/#arguments
+[alter_job_samples]: /api/:currentVersion:/jobs-automation/alter_job/#samples
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
+[tsdb-release-2-19-3]: https://github.com/timescale/timescaledb/releases/tag/2.19.3
\ No newline at end of file
diff --git a/api/hypercore/alter_table.md b/api/hypercore/alter_table.md
index ffffa3acd5..a1ef5b57ce 100644
--- a/api/hypercore/alter_table.md
+++ b/api/hypercore/alter_table.md
@@ -15,9 +15,15 @@ import EarlyAccess from "versionContent/_partials/_early_access_2_18_0.mdx";
# ALTER TABLE ($HYPERCORE)
-Enable the $COLUMNSTORE or change the $COLUMNSTORE settings for a $HYPERTABLE. The settings are applied on a per-chunk basis. You do not need to convert the entire $HYPERTABLE back to the $ROWSTORE before changing the settings. The new settings apply only to the chunks that have not yet been converted to $COLUMNSTORE, the existing chunks in the $COLUMNSTORE do not change. This means that chunks with different $COLUMNSTORE settings can co-exist in the same $HYPERTABLE.
+Enable the $COLUMNSTORE or change the $COLUMNSTORE settings for a $HYPERTABLE. The settings are applied on a per-chunk
+basis. You **do not** need to convert the entire $HYPERTABLE back to the $ROWSTORE before changing the settings. The new
+settings apply only to the chunks that have not yet been converted to $COLUMNSTORE, the existing chunks in the
+$COLUMNSTORE do not change. This means that chunks with different $COLUMNSTORE settings can co-exist in the
+same $HYPERTABLE.
-$TIMESCALE_DB calculates default $COLUMNSTORE settings for each chunk when it is created. These settings apply to each chunk, and not the entire hypertable. To explicitly disable the defaults, set a setting to an empty string. To remove the current configuration and re-enable the defaults, call `ALTER TABLE RESET ();`.
+$TIMESCALE_DB calculates default $COLUMNSTORE settings for each chunk when it is created. These settings apply to each
+chunk, and not the entire hypertable. To explicitly disable the defaults, set a setting to an empty string. To remove
+the current configuration and re-enable the defaults, call `ALTER TABLE RESET ();`.
After you have enabled the $COLUMNSTORE, either:
- [add_columnstore_policy][add_columnstore_policy]: create a [job][job] that automatically moves chunks in a hypertable to the $COLUMNSTORE at a
@@ -28,12 +34,12 @@ After you have enabled the $COLUMNSTORE, either:
## Samples
-To enable the $COLUMNSTORE:
+To enable the $COLUMNSTORE using `ALTER TABLE`:
-- **Configure a hypertable that ingests device data to use the $COLUMNSTORE**:
+- **Configure a $HYPERTABLE that ingests device data to use the $COLUMNSTORE**:
- In this example, the `metrics` hypertable is often queried about a specific device or set of devices.
- Segment the hypertable by `device_id` to improve query performance.
+ In this example, the `metrics` $HYPERTABLE is often queried about a specific device or set of devices.
+ Segment the $HYPERTABLE by `device_id` to improve query performance.
```sql
ALTER TABLE metrics SET(
diff --git a/api/hypercore/chunk_columnstore_stats.md b/api/hypercore/chunk_columnstore_stats.md
index c8147a674e..e9fb181279 100644
--- a/api/hypercore/chunk_columnstore_stats.md
+++ b/api/hypercore/chunk_columnstore_stats.md
@@ -16,10 +16,11 @@ import Since2180 from "versionContent/_partials/_since_2_18_0.mdx";
Retrieve statistics about the chunks in the $COLUMNSTORE
`chunk_columnstore_stats` returns the size of chunks in the $COLUMNSTORE, these values are computed when you call either:
-- [add_columnstore_policy][add_columnstore_policy]: create a [job][job] that automatically moves chunks in a hypertable to the $COLUMNSTORE at a
- specific time interval.
-- [convert_to_columnstore][convert_to_columnstore]: manually add a specific chunk in a hypertable to the $COLUMNSTORE.
-
+- [CREATE TABLE][hypertable-create-table]: create a $HYPERTABLE with a default [job][job] that automatically
+ moves chunks in a $HYPERTABLE to the $COLUMNSTORE at a specific time interval.
+- [add_columnstore_policy][add_columnstore_policy]: create a [job][job] on an existing $HYPERTABLE that automatically
+ moves chunks in a $HYPERTABLE to the $COLUMNSTORE at a specific time interval.
+- [convert_to_columnstore][convert_to_columnstore]: manually add a specific chunk in a $HYPERTABLE to the $COLUMNSTORE.
Inserting into a chunk in the $COLUMNSTORE does not change the chunk size. For more information about how to compute
chunk sizes, see [chunks_detailed_size][chunks_detailed_size].
@@ -108,3 +109,4 @@ To retrieve statistics about chunks:
[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
[job]: /api/:currentVersion:/jobs-automation/add_job/
[chunks_detailed_size]: /api/:currentVersion:/hypertable/chunks_detailed_size/
+[hypertable-create-table]: /api/:currentVersion:/hypertable/create_table/
diff --git a/api/hypercore/index.md b/api/hypercore/index.md
index 06b825f078..af49d8079a 100644
--- a/api/hypercore/index.md
+++ b/api/hypercore/index.md
@@ -8,9 +8,9 @@ api:
license: community
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
import Since2180 from "versionContent/_partials/_since_2_18_0.mdx";
import HypercoreIntro from "versionContent/_partials/_hypercore-intro.mdx";
+import CreateHypertableProcedure from "versionContent/_partials/_hypercore_create_hypertable_columnstore_policy.mdx";
# Hypercore
@@ -24,43 +24,7 @@ Best practice for using $HYPERCORE is to:
-1. **Enable $COLUMNSTORE**
-
- Create a [$HYPERTABLE][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
- For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
- use most often to filter your data. For example:
-
- * [Use `CREATE TABLE` for a $HYPERTABLE][hypertable-create-table]
-
- ```sql
- CREATE TABLE crypto_ticks (
- "time" TIMESTAMPTZ,
- symbol TEXT,
- price DOUBLE PRECISION,
- day_volume NUMERIC
- ) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time',
- tsdb.segmentby='symbol',
- tsdb.orderby='time DESC'
- );
- ```
-
-
- * [Use `ALTER MATERIALIZED VIEW` for a continuous aggregate][compression_continuous-aggregate]
- ```sql
- ALTER MATERIALIZED VIEW assets_candlestick_daily set (
- timescaledb.enable_columnstore = true,
- timescaledb.segmentby = 'symbol' );
- ```
-
-1. **Add a policy to move chunks to the $COLUMNSTORE at a specific time interval**
-
- For example, 7 days after the data was added to the table:
- ``` sql
- CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '7d');
- ```
- See [add_columnstore_policy][add_columnstore_policy].
+
1. **View the policies that you set or the policies that already exist**
diff --git a/api/hypertable/create_table.md b/api/hypertable/create_table.md
index 05ce9a269f..8f777fa6e5 100644
--- a/api/hypertable/create_table.md
+++ b/api/hypertable/create_table.md
@@ -9,6 +9,9 @@ api:
products: [cloud, mst, self_hosted]
---
+
+import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
import Since2200 from "versionContent/_partials/_since_2_20_0.mdx";
import DimensionInfo from "versionContent/_partials/_dimensions_info.mdx";
import HypercoreDirectCompress from "versionContent/_partials/_hypercore-direct-compress.mdx";
@@ -24,49 +27,52 @@ a $HYPERTABLE is partitioned on the time dimension. To add secondary dimensions
[add_dimension][add-dimension]. To convert an existing relational table into a $HYPERTABLE, call
[create_hypertable][create_hypertable].
-As the data cools and becomes more suited for analytics, [add a columnstore policy][add_columnstore_policy] so your data
-is automatically converted to the $COLUMNSTORE after a specific time interval. This columnar format enables fast
-scanning and aggregation, optimizing performance for analytical workloads while also saving significant storage space.
-In the $COLUMNSTORE conversion, $HYPERTABLE chunks are compressed by up to 98%, and organized for efficient,
-large-scale queries. This columnar format enables fast scanning and aggregation, optimizing performance for analytical
-workloads. You can also manually [convert chunks][convert_to_columnstore] in a $HYPERTABLE to the $COLUMNSTORE.
+
$HYPERTABLE_CAP to $HYPERTABLE foreign keys are not allowed, all other combinations are permitted.
-The [$COLUMNSTORE][hypercore] settings are applied on a per-chunk basis. You can change the settings by calling [ALTER TABLE][alter_table_hypercore] without first converting the entire $HYPERTABLE back to the [$ROWSTORE][hypercore]. The new settings apply only to the chunks that have not yet been converted to $COLUMNSTORE, the existing chunks in the $COLUMNSTORE do not change. Similarly, if you [remove an existing columnstore policy][remove_columnstore_policy] and then [add a new one][add_columnstore_policy], the new policy applies only to the unconverted chunks. This means that chunks with different $COLUMNSTORE settings can co-exist in the same $HYPERTABLE.
+The [$COLUMNSTORE][hypercore] settings are applied on a per-chunk basis. You can change the settings by calling
+[ALTER TABLE][alter_table_hypercore] without first converting the entire $HYPERTABLE back to the [$ROWSTORE][hypercore].
+The new settings apply only to the chunks that have not yet been converted to $COLUMNSTORE, the existing chunks in the
+$COLUMNSTORE do not change. Similarly, if you [remove an existing columnstore policy][remove_columnstore_policy] and then
+[add a new one][add_columnstore_policy], the new policy applies only to the unconverted chunks. This means that chunks
+with different $COLUMNSTORE settings can co-exist in the same $HYPERTABLE.
-$TIMESCALE_DB calculates default $COLUMNSTORE settings for each chunk when it is created. These settings apply to each chunk, and not the entire hypertable. To explicitly disable the defaults, set a setting to an empty string.
+$TIMESCALE_DB calculates default $COLUMNSTORE settings for each chunk when it is created. These settings apply to each
+chunk, and not the entire hypertable. To explicitly disable the defaults, set a setting to an empty string.
`CREATE TABLE` extends the standard $PG [CREATE TABLE][pg-create-table]. This page explains the features and
arguments specific to $TIMESCALE_DB.
+
+
+
+
+
+
## Samples
- **Create a $HYPERTABLE partitioned on the time dimension and enable $COLUMNSTORE**:
- 1. Create the $HYPERTABLE:
+ ```sql
+ CREATE TABLE crypto_ticks (
+ "time" TIMESTAMPTZ,
+ symbol TEXT,
+ price DOUBLE PRECISION,
+ day_volume NUMERIC
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.segmentby='symbol',
+ tsdb.orderby='time DESC'
+ );
+ ```
- ```sql
- CREATE TABLE crypto_ticks (
- "time" TIMESTAMPTZ,
- symbol TEXT,
- price DOUBLE PRECISION,
- day_volume NUMERIC
- ) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time',
- tsdb.segmentby='symbol',
- tsdb.orderby='time DESC'
- );
- ```
-
- 1. Enable $HYPERCORE by adding a columnstore policy:
-
- ```sql
- CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '1d');
- ```
+ When you create a $HYPERTABLE using `CREATE TABLE WITH`, $TIMESCALE_DB automatically creates a
+ [columnstore policy][add_columnstore_policy] that uses the chunk interval as the compression interval, with a default
+ schedule interval of 1 day. The default partitioning column is automatically selected as the first column with a
+ timestamp or timestampz data type.
- **Create a $HYPERTABLE partitioned on the time with fewer chunks based on time interval**:
@@ -77,7 +83,6 @@ arguments specific to $TIMESCALE_DB.
value float
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.chunk_interval=3453
);
```
@@ -109,9 +114,7 @@ arguments specific to $TIMESCALE_DB.
-
-
-
+
- **Enable data compression during ingestion**:
@@ -119,7 +122,7 @@ arguments specific to $TIMESCALE_DB.
1. Create a $HYPERTABLE:
```sql
- CREATE TABLE t(time timestamptz, device text, value float) WITH (tsdb.hypertable,tsdb.partition_column='time');
+ CREATE TABLE t(time timestamptz, device text, value float) WITH (tsdb.hypertable);
```
1. Copy data into the $HYPERTABLE:
You achieve the highest insert rate using binary format. CSV and text format are also supported.
@@ -157,17 +160,17 @@ WITH (
)
```
-| Name | Type | Default | Required | Description |
-|--------------------------------|------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| `tsdb.hypertable` |BOOLEAN| `true` | ✖ | Create a new [hypertable][hypertable-docs] for time-series data rather than a standard $PG relational table. |
-| `tsdb.partition_column` |TEXT| `true` | ✖ | Set the time column to automatically partition your time-series data by. |
-| `tsdb.chunk_interval` |TEXT| `7 days` | ✖ | Change this to better suit your needs. For example, if you set `chunk_interval` to 1 day, each chunk stores data from the same day. Data from different days is stored in different chunks. |
-| `tsdb.create_default_indexes` | BOOLEAN | `true` | ✖ | Set to `false` to not automatically create indexes.
The default indexes are: - On all hypertables, a descending index on `partition_column`
- On hypertables with space partitions, an index on the space parameter and `partition_column`
|
-| `tsdb.associated_schema` |REGCLASS| `_timescaledb_internal` | ✖ | Set the schema name for internal hypertable tables. |
-| `tsdb.associated_table_prefix` |TEXT| `_hyper` | ✖ | Set the prefix for the names of internal hypertable chunks. |
-| `tsdb.orderby` |TEXT| Descending order on the time column in `table_name`. | ✖| The order in which items are used in the $COLUMNSTORE. Specified in the same way as an `ORDER BY` clause in a `SELECT` query. Setting `tsdb.orderby` automatically creates an implicit min/max sparse index on the `orderby` column. |
-| `tsdb.segmentby` |TEXT| $TIMESCALE_DB looks at [`pg_stats`](https://www.postgresql.org/docs/current/view-pg-stats.html) and determines an appropriate column based on the data cardinality and distribution. If `pg_stats` is not available, $TIMESCALE_DB looks for an appropriate column from the existing indexes. | ✖| Set the list of columns used to segment data in the $COLUMNSTORE for `table`. An identifier representing the source of the data such as `device_id` or `tags_id` is usually a good candidate. |
-|`tsdb.sparse_index`| TEXT | $TIMESCALE_DB evaluates the columns you already have indexed, checks which data types are a good fit for sparse indexing, then creates a sparse index as an optimization. | ✖ | Configure the sparse indexes for compressed chunks. Requires setting `tsdb.orderby`. Supported index types include: `bloom()`: a probabilistic index, effective for `=` filters. Cannot be applied to `tsdb.orderby` columns. `minmax()`: stores min/max values for each compressed chunk. Setting `tsdb.orderby` automatically creates an implicit min/max sparse index on the `orderby` column. Define multiple indexes using a comma-separated list. You can set only one index per column. Set to an empty string to avoid using sparse indexes and explicitly disable the default behavior. |
+| Name | Type | Default | Required | Description |
+|--------------------------------|------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `tsdb.hypertable` |BOOLEAN| `true` | ✖ | Create a new [hypertable][hypertable-docs] for time-series data rather than a standard $PG relational table. |
+| `tsdb.partition_column` |TEXT| The first column in the table with a timestamp data type | ✖ | Set the time column to automatically partition your time-series data by. |
+| `tsdb.chunk_interval` |TEXT| `7 days` | ✖ | Change this to better suit your needs. For example, if you set `chunk_interval` to 1 day, each chunk stores data from the same day. Data from different days is stored in different chunks. |
+| `tsdb.create_default_indexes` | BOOLEAN | `true` | ✖ | Set to `false` to not automatically create indexes.
The default indexes are: - On all hypertables, a descending index on `partition_column`
- On hypertables with space partitions, an index on the space parameter and `partition_column`
|
+| `tsdb.associated_schema` |REGCLASS| `_timescaledb_internal` | ✖ | Set the schema name for internal hypertable tables. |
+| `tsdb.associated_table_prefix` |TEXT| `_hyper` | ✖ | Set the prefix for the names of internal hypertable chunks. |
+| `tsdb.orderby` |TEXT| Descending order on the time column in `table_name`. | ✖| The order in which items are used in the $COLUMNSTORE. Specified in the same way as an `ORDER BY` clause in a `SELECT` query. Setting `tsdb.orderby` automatically creates an implicit min/max sparse index on the `orderby` column. |
+| `tsdb.segmentby` |TEXT| $TIMESCALE_DB looks at [`pg_stats`](https://www.postgresql.org/docs/current/view-pg-stats.html) and determines an appropriate column based on the data cardinality and distribution. If `pg_stats` is not available, $TIMESCALE_DB looks for an appropriate column from the existing indexes. | ✖| Set the list of columns used to segment data in the $COLUMNSTORE for `table`. An identifier representing the source of the data such as `device_id` or `tags_id` is usually a good candidate. |
+|`tsdb.sparse_index`| TEXT | $TIMESCALE_DB evaluates the columns you already have indexed, checks which data types are a good fit for sparse indexing, then creates a sparse index as an optimization. | ✖ | Configure the sparse indexes for compressed chunks. Requires setting `tsdb.orderby`. Supported index types include: `bloom()`: a probabilistic index, effective for `=` filters. Cannot be applied to `tsdb.orderby` columns. `minmax()`: stores min/max values for each compressed chunk. Setting `tsdb.orderby` automatically creates an implicit min/max sparse index on the `orderby` column. Define multiple indexes using a comma-separated list. You can set only one index per column. Set to an empty string to avoid using sparse indexes and explicitly disable the default behavior. |
@@ -182,7 +185,7 @@ $TIMESCALE_DB returns a simple message indicating success or failure.
[hypertable-docs]: /use-timescale/:currentVersion:/hypertables/
[declarative-partitioning]: https://www.postgresql.org/docs/current/ddl-partitioning.html#DDL-PARTITIONING-DECLARATIVE
[inheritance]: https://www.postgresql.org/docs/current/ddl-partitioning.html#DDL-PARTITIONING-USING-INHERITANCE
-[migrate-data]: /api/:currentVersion:/hypertable/create_table/#arguments
+[create_table_arguments]: /api/:currentVersion:/hypertable/create_table/#arguments
[dimension-info]: /api/:currentVersion:/hypertable/create_table/#dimension-info
[chunk_interval]: /api/:currentVersion:/hypertable/set_chunk_time_interval/
[about-constraints]: /use-timescale/:currentVersion:/schema-management/about-constraints
@@ -203,6 +206,7 @@ $TIMESCALE_DB returns a simple message indicating success or failure.
[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
[bloom-filters]: https://en.wikipedia.org/wiki/Bloom_filter
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
-[uuidv7_functions]: /api/:currentVersion:/uuid-functions/
\ No newline at end of file
+[uuidv7_functions]: /api/:currentVersion:/uuid-functions/
+[informational-views]: /api/:currentVersion:/informational-views/jobs/
+[alter_job_samples]: /api/:currentVersion:/jobs-automation/alter_job/#samples
\ No newline at end of file
diff --git a/api/hypertable/enable_chunk_skipping.md b/api/hypertable/enable_chunk_skipping.md
index 0c50ba8338..51262a8c54 100644
--- a/api/hypertable/enable_chunk_skipping.md
+++ b/api/hypertable/enable_chunk_skipping.md
@@ -10,7 +10,7 @@ api:
products: [cloud, mst, self_hosted]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
import EarlyAccess2171 from "versionContent/_partials/_early_access_2_17_1.mdx";
@@ -65,14 +65,13 @@ CREATE TABLE conditions (
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
SELECT enable_chunk_skipping('conditions', 'device_id');
```
-
+
## Arguments
diff --git a/api/hypertable/index.md b/api/hypertable/index.md
index 015c15e036..1c7cd2a29d 100644
--- a/api/hypertable/index.md
+++ b/api/hypertable/index.md
@@ -6,6 +6,7 @@ products: [cloud, mst, self_hosted]
---
import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
import HypertableOverview from "versionContent/_partials/_hypertable-intro.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Hypertables and chunks
@@ -14,41 +15,31 @@ import HypertableOverview from "versionContent/_partials/_hypertable-intro.mdx";
For more information about using hypertables, including chunk size partitioning,
see the [hypertable section][hypertable-docs].
-## The hypertable workflow
+To create a [$HYPERTABLE][hypertables-section] for your time-series data, use [CREATE TABLE][hypertable-create-table].
+For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+use most often to filter your data. For example:
-Best practice for using a $HYPERTABLE is to:
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ NOT NULL,
+ location TEXT NOT NULL,
+ device TEXT NOT NULL,
+ temperature DOUBLE PRECISION NULL,
+ humidity DOUBLE PRECISION NULL
+) WITH (
+ tsdb.hypertable,
+ tsdb.segmentby = 'device',
+ tsdb.orderby = 'time DESC'
+);
+```
-
+
-1. **Create a $HYPERTABLE**
+
- Create a [$HYPERTABLE][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
- For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
- use most often to filter your data. For example:
+
- ```sql
- CREATE TABLE conditions (
- time TIMESTAMPTZ NOT NULL,
- location TEXT NOT NULL,
- device TEXT NOT NULL,
- temperature DOUBLE PRECISION NULL,
- humidity DOUBLE PRECISION NULL
- ) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time',
- tsdb.segmentby = 'device',
- tsdb.orderby = 'time DESC'
- );
- ```
-
-
-1. **Set the $COLUMNSTORE policy**
-
- ```sql
- CALL add_columnstore_policy('conditions', after => INTERVAL '1d');
- ```
-
-
+
[create_hypertable]: /api/:currentVersion:/hypertable/create_hypertable/
[hypertable-docs]: /use-timescale/:currentVersion:/hypertables/
diff --git a/api/jobs-automation/alter_job.md b/api/jobs-automation/alter_job.md
index 965122f02f..e5de389cf5 100644
--- a/api/jobs-automation/alter_job.md
+++ b/api/jobs-automation/alter_job.md
@@ -23,75 +23,7 @@ scheduled $JOBs, as well as in `timescaledb_information.job_stats`. The
`job_stats` view also gives information about when each $JOB was last run and
other useful statistics for deciding what the new schedule should be.
-## Samples
-
-Reschedules $JOB ID `1000` so that it runs every two days:
-
-```sql
-SELECT alter_job(1000, schedule_interval => INTERVAL '2 days');
-```
-
-Disables scheduling of the compression policy on the `conditions` hypertable:
-
-```sql
-SELECT alter_job(job_id, scheduled => false)
-FROM timescaledb_information.jobs
-WHERE proc_name = 'policy_compression' AND hypertable_name = 'conditions'
-```
-
-Reschedules continuous aggregate $JOB ID `1000` so that it next runs at 9:00:00 on 15 March, 2020:
-
-```sql
-SELECT alter_job(1000, next_start => '2020-03-15 09:00:00.0+00');
-```
-
-## Required arguments
-
-|Name|Type|Description|
-|-|-|-|
-|`job_id`|`INTEGER`|The ID of the policy $JOB being modified|
-
-## Optional arguments
-
-|Name|Type| Description |
-|-|-|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-|`schedule_interval`|`INTERVAL`| The interval at which the job runs. Defaults to 24 hours. |
-|`max_runtime`|`INTERVAL`| The maximum amount of time the job is allowed to run by the background worker scheduler before it is stopped. |
-|`max_retries`|`INTEGER`| The number of times the job is retried if it fails. |
-|`retry_period`|`INTERVAL`| The amount of time the scheduler waits between retries of the job on failure. |
-|`scheduled`|`BOOLEAN`| Set to `FALSE` to exclude this job from being run as background job. |
-|`config`|`JSONB`| $JOB_CAP-specific configuration, passed to the function when it runs. This includes: verbose_log: boolean, defaults to false. Enable verbose logging output when running the compression policy.maxchunks_to_compress: integer, defaults to 0 (no limit). The maximum number of chunks to compress during a policy run.recompress: boolean, defaults to true. Recompress partially compressed chunks.compress_after: see [add_compression_policy][add-policy].compress_created_before: see [add_compression_policy][add-policy]. |
-|`next_start`|`TIMESTAMPTZ`| The next time at which to run the job. The job can be paused by setting this value to `infinity`, and restarted with a value of `now()`. |
-|`if_exists`|`BOOLEAN`| Set to `true`to issue a notice instead of an error if the job does not exist. Defaults to false. |
-|`check_config`|`REGPROC`| A function that takes a single argument, the `JSONB` `config` structure. The function is expected to raise an error if the configuration is not valid, and return nothing otherwise. Can be used to validate the configuration when updating a job. Only functions, not procedures, are allowed as values for `check_config`. |
-|`fixed_schedule`|`BOOLEAN`| To enable fixed scheduled job runs, set to `TRUE`. |
-|`initial_start`|`TIMESTAMPTZ`| Set the time when the `fixed_schedule` job run starts. For example, `19:10:25-07`. |
-|`timezone`|`TEXT`| Address the 1-hour shift in start time when clocks change from [Daylight Saving Time to Standard Time](https://en.wikipedia.org/wiki/Daylight_saving_time). For example, `America/Sao_Paulo`. |
-
-When a $JOB begins, the `next_start` parameter is set to `infinity`. This
-prevents the $JOB from attempting to be started again while it is running. When
-the $JOB completes, whether or not the job is successful, the parameter is
-automatically updated to the next computed start time.
-
-Note that altering the `next_start` value is only effective for the next
-execution of the $JOB in case of fixed schedules. On the next execution, it will
-automatically return to the schedule.
-
-## Returns
-
-|Column|Type| Description |
-|-|-|---------------------------------------------------------------------------------------------------------------|
-|`job_id`|`INTEGER`| The ID of the $JOB being modified |
-|`schedule_interval`|`INTERVAL`| The interval at which the $JOB runs. Defaults to 24 hours |
-|`max_runtime`|`INTERVAL`| The maximum amount of time the $JOB is allowed to run by the background worker scheduler before it is stopped |
-|`max_retries`|INTEGER| The number of times the $JOB is retried if it fails |
-|`retry_period`|`INTERVAL`| The amount of time the scheduler waits between retries of the $JOB on failure |
-|`scheduled`|`BOOLEAN`| Returns `true` if the $JOB is executed by the TimescaleDB scheduler |
-|`config`|`JSONB`| $JOB_CAPs-specific configuration, passed to the function when it runs |
-|`next_start`|`TIMESTAMPTZ`| The next time to run the $JOB |
-|`check_config`|`TEXT`| The function used to validate updated $JOB configurations |
-
-## Calculation of next start on failure
+### Calculate the next start on failure
When a $JOB run results in a runtime failure, the next start of the $JOB is calculated taking into account both its `retry_period` and `schedule_interval`.
The `next_start` time is calculated using the following formula:
@@ -100,8 +32,6 @@ next_start = finish_time + consecutive_failures * retry_period ± jitter
```
where jitter (± 13%) is added to avoid the "thundering herds" effect.
-
-
To ensure that the `next_start` time is not put off indefinitely or produce timestamps so large they end up out of range, it is capped at 5*`schedule_interval`.
Also, more than 20 consecutive failures are not considered, so if the number of consecutive failures is higher, then it multiplies by 20.
@@ -111,7 +41,95 @@ There is a distinction between runtime failures that do not cause the $JOB to cr
In the event of a $JOB crash, the next start calculation follows the same formula,
but it is always at least 5 minutes after the $JOB's last finish, to give an operator enough time to disable it before another crash.
-
-[add-policy]: /api/:currentVersion:/compression/add_compression_policy/#required-arguments
\ No newline at end of file
+## Samples
+
+- **Reschedule $JOB ID `1000` so that it runs every two days**:
+
+ ```sql
+ SELECT alter_job(1000, schedule_interval => INTERVAL '2 days');
+ ```
+
+- **Disable scheduling of the compression policy on the `conditions` hypertable**:
+
+ ```sql
+ SELECT alter_job(job_id, scheduled => false)
+ FROM timescaledb_information.jobs
+ WHERE proc_name = 'policy_compression' AND hypertable_name = 'conditions'
+ ```
+
+- **Reschedule continuous aggregate $JOB ID `1000` so that it next runs at 9:00:00 on 15 March, 2020**:
+
+ ```sql
+ SELECT alter_job(1000, next_start => '2020-03-15 09:00:00.0+00');
+ ```
+
+- **Alter a columnstore_policy**:
+
+ You can pause and restart a columnstore policy, change how often the policy runs and the job scheduling.
+ To do this:
+
+ 1. Find the job ID for the columnstore policy:
+ ```sql
+ SELECT job_id, hypertable_name, config
+ FROM timescaledb_information.jobs
+ WHERE proc_name = 'policy_compression';
+ ```
+ 1. Update the policy:
+
+ For example, to change the compression interval after 30 days instead of 7:
+ ```sql
+ SELECT alter_job(1000, config => '{"compress_after": "30 days"}');
+ ```
+ However, to change the `after` or `created_before`, the compression settings, or the $HYPERTABLE
+ the policy is acting on, you must [remove the columnstore policy][remove_columnstore_policy] and
+ [add a new one][add_columnstore_policy].
+
+
+
+## Arguments
+
+| Name | Type | Default | Required | Description |
+|--------------------------------|------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `job_id` |INTEGER| - | ✔ | The ID of the policy $JOB being modified. |
+| `schedule_interval` |INTERVAL| 24 hours | ✖ | The interval at which the job runs. |
+| `max_runtime` |INTERVAL| - | ✖ | The maximum amount of time the job is allowed to run by the background worker scheduler before it is stopped. |
+| `max_retries` | INTEGER | - | ✖ | The number of times the job is retried if it fails. |
+| `retry_period` |INTERVAL| - | ✖ | The amount of time the scheduler waits between retries of the job on failure. |
+| `scheduled` |BOOLEAN| `true` | ✖ | Set to `false` to exclude this job from being run as a background job. |
+| `config` |JSONB| - | ✖| $JOB_CAP-specific configuration, passed to the function when it runs. This includes: - `verbose_log`: boolean, defaults to `false`. Enable verbose logging output when running the compression policy.
- `maxchunks_to_compress`: integer, defaults to `0` (no limit). The maximum number of chunks to compress during a policy run.
- `recompress`: boolean, defaults to `true`. Recompress partially compressed chunks.
- `compress_after`: see [`add_compression_policy`][add-policy].
- `compress_created_before`: see [`add_compression_policy`][add-policy].
|
+| `next_start` |TIMESTAMPTZ| - | ✖ | The next time at which to run the job. The job can be paused by setting this value to `infinity`, and restarted with a value of `now()`. |
+| `if_exists` |BOOLEAN| `false` | ✖ | Set to `true` to issue a notice instead of an error if the job does not exist. |
+| `check_config` | REGPROC | - | ✖ | A function that takes a single argument, the `JSONB` `config` structure. The function is expected to raise an error if the configuration is not valid, and return nothing otherwise. Can be used to validate the configuration when updating a job. Only functions, not procedures, are allowed as values for `check_config`. |
+| `fixed_schedule` |BOOLEAN| `false` | ✖| To enable fixed scheduled job runs, set to `true`. |
+|`initial_start`| TIMESTAMPTZ | - | ✖ | Set the time when the `fixed_schedule` job run starts. For example, `19:10:25-07`. |
+| `timezone` |TEXT| `UTC` | ✖ | Address the 1-hour shift in start time when clocks change from [Daylight Saving Time to Standard Time](https://en.wikipedia.org/wiki/Daylight_saving_time). For example, `America/Sao_Paulo`. |
+
+When a $JOB begins, the `next_start` parameter is set to `infinity`. This
+prevents the $JOB from attempting to be started again while it is running. When
+the $JOB completes, whether or not the job is successful, the parameter is
+automatically updated to the next computed start time.
+
+Note that altering the `next_start` value is only effective for the next
+execution of the $JOB in case of fixed schedules. On the next execution, it will
+automatically return to the schedule.
+
+## Returns
+
+| Column | Type | Description |
+|--------------------------------|------------------|---------------------------------------------------------------------------------------------------------------|
+|`job_id` |INTEGER | The ID of the $JOB being modified |
+|`schedule_interval` |INTERVAL | The interval at which the $JOB runs. Defaults to 24 hours |
+|`max_runtime` |INTERVAL | The maximum amount of time the $JOB is allowed to run by the background worker scheduler before it is stopped |
+|`max_retries` |INTEGER | The number of times the $JOB is retried if it fails |
+|`retry_period` |INTERVAL | The amount of time the scheduler waits between retries of the $JOB on failure |
+|`scheduled` |BOOLEAN | Returns `true` if the $JOB is executed by the TimescaleDB scheduler |
+|`config` |JSONB | $JOB_CAP-specific configuration, passed to the function when it runs |
+|`next_start` |TIMESTAMPTZ | The next time to run the $JOB |
+|`check_config` |TEXT | The function used to validate updated $JOB configurations |
+
+
+[add-policy]: /api/:currentVersion:/compression/add_compression_policy/#required-arguments
+[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
\ No newline at end of file
diff --git a/getting-started/try-key-features-timescale-products.md b/getting-started/try-key-features-timescale-products.md
index 1a65536eb0..03054ee956 100644
--- a/getting-started/try-key-features-timescale-products.md
+++ b/getting-started/try-key-features-timescale-products.md
@@ -7,10 +7,11 @@ content_group: Getting started
import HASetup from 'versionContent/_partials/_high-availability-setup.mdx';
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
import HypercoreIntroShort from "versionContent/_partials/_hypercore-intro-short.mdx";
import HypercoreDirectCompress from "versionContent/_partials/_hypercore-direct-compress.mdx";
import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
+
import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Try the key features in $COMPANY products
@@ -80,7 +81,7 @@ relational and time-series data from external files.
To more fully understand how to create a $HYPERTABLE, how $HYPERTABLEs work, and how to optimize them for
performance by tuning $CHUNK intervals and enabling chunk skipping, see
- [the $HYPERTABLEs documentation][hypertables-section].
+ [the $HYPERTABLEs documentation][hypertables-section].
@@ -129,12 +130,10 @@ relational and time-series data from external files.
day_volume NUMERIC
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.segmentby = 'symbol'
);
```
-
-
+
- For the relational data:
@@ -175,47 +174,6 @@ relational and time-series data from external files.
-## Enhance query performance for analytics
-
-$HYPERCORE_CAP is the $TIMESCALE_DB hybrid row-columnar storage engine, designed specifically for real-time
-analytics and
-powered by time-series data. The advantage of $HYPERCORE is its ability to seamlessly switch between row-oriented and
-column-oriented storage. This flexibility enables $TIMESCALE_DB to deliver the best of both worlds, solving the key
-challenges in real-time analytics.
-
-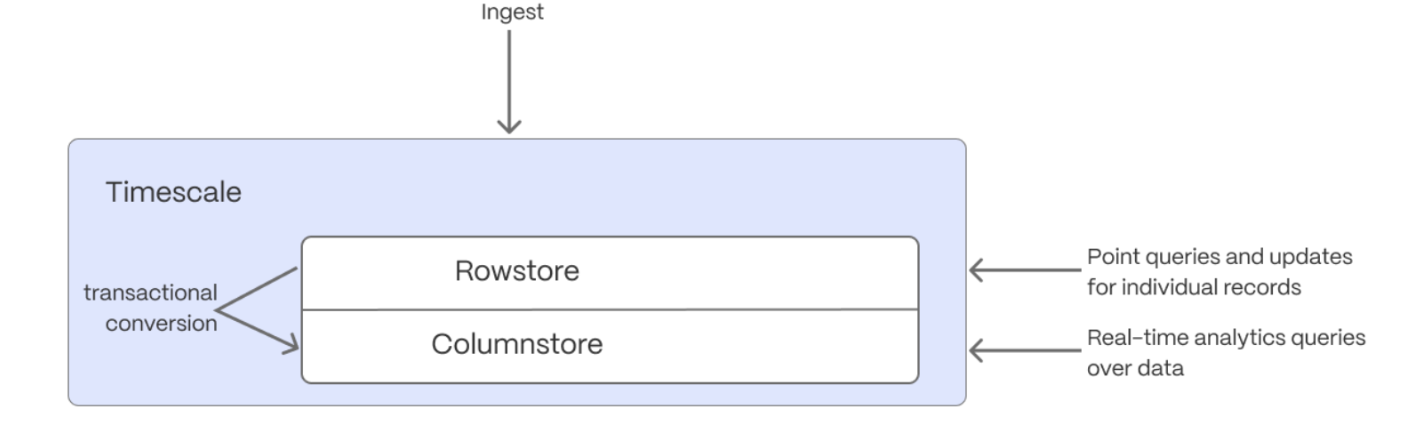
-
-When $TIMESCALE_DB converts $CHUNKs from the $ROWSTORE to the $COLUMNSTORE, multiple records are grouped into a single row.
-The columns of this row hold an array-like structure that stores all the data. Because a single row takes up less disk
-space, you can reduce your $CHUNK size by up to 98%, and can also speed up your queries. This helps you save on storage costs,
-and keeps your queries operating at lightning speed.
-
-$HYPERCORE is enabled by default when you call [CREATE TABLE][hypertable-create-table]. Best practice is to compress
-data that is no longer needed for highest performance queries, but is still accessed regularly in the $COLUMNSTORE.
-For example, yesterday's market data.
-
-
-
-1. **Add a policy to convert $CHUNKs to the $COLUMNSTORE at a specific time interval**
-
- For example, yesterday's data:
- ``` sql
- CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '1d');
- ```
- If you have not configured a `segmentby` column, $TIMESCALE_DB chooses one for you based on the data in your
- $HYPERTABLE. For more information on how to tune your $HYPERTABLEs for the best performance, see
- [efficient queries][secondary-indexes].
-
-1. **View your data space saving**
-
- When you convert data to the $COLUMNSTORE, as well as being optimized for analytics, it is compressed by more than
- 90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
- saved, click `Explorer` > `public` > `crypto_ticks`.
-
- 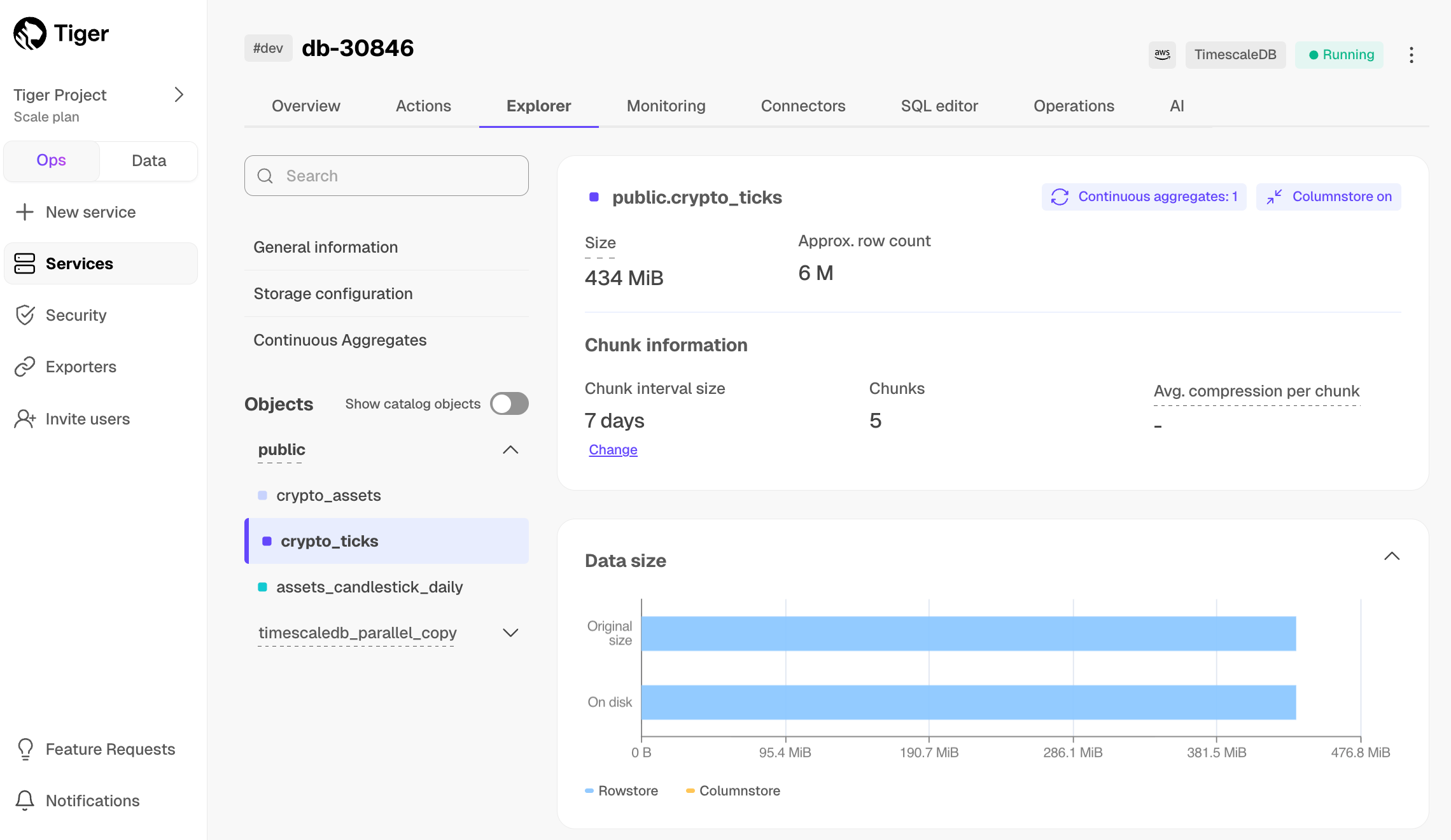
-
-
-
## Write fast and efficient analytical queries
Aggregation is a way of combing data to get insights from it. Average, sum, and count are all
diff --git a/integrations/amazon-sagemaker.md b/integrations/amazon-sagemaker.md
index bf18a12d26..be3cd98701 100644
--- a/integrations/amazon-sagemaker.md
+++ b/integrations/amazon-sagemaker.md
@@ -6,7 +6,7 @@ keywords: [connect, integrate, amazon, aws, sagemaker]
---
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Integrate Amazon SageMaker with $CLOUD_LONG
@@ -44,11 +44,10 @@ Create a table in $SERVICE_LONG to store model predictions generated by SageMake
model_name TEXT NOT NULL,
prediction DOUBLE PRECISION NOT NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
diff --git a/integrations/apache-kafka.md b/integrations/apache-kafka.md
index c1d944ac45..6a3bca0b17 100644
--- a/integrations/apache-kafka.md
+++ b/integrations/apache-kafka.md
@@ -7,7 +7,7 @@ keywords: [Apache Kafka, integrations]
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
import IntegrationApacheKafka from "versionContent/_partials/_integration-apache-kafka-install.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Integrate Apache Kafka with $CLOUD_LONG
@@ -93,11 +93,10 @@ To prepare your $SERVICE_LONG for Kafka integration:
name TEXT,
city TEXT
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='created_at'
+ tsdb.hypertable
);
```
-
+
diff --git a/integrations/aws-lambda.md b/integrations/aws-lambda.md
index 875092121b..fa42ea286d 100644
--- a/integrations/aws-lambda.md
+++ b/integrations/aws-lambda.md
@@ -6,7 +6,7 @@ keywords: [connect, integrate, aws, lambda]
---
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Integrate AWS Lambda with Tiger
@@ -46,11 +46,10 @@ Create a table in $SERVICE_LONG to store time-series data.
sensor_id TEXT NOT NULL,
value DOUBLE PRECISION NOT NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
diff --git a/integrations/supabase.md b/integrations/supabase.md
index ecfdd7fb25..7447372b4a 100644
--- a/integrations/supabase.md
+++ b/integrations/supabase.md
@@ -6,7 +6,7 @@ keywords: [integrate]
---
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Integrate Supabase with $CLOUD_LONG
@@ -40,11 +40,10 @@ To set up a $SERVICE_LONG optimized for analytics to receive data from Supabase:
origin_time timestamptz NOT NULL,
name TEXT
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
1. **Optimize cooling data for analytics**
diff --git a/self-hosted/migration/same-db.md b/self-hosted/migration/same-db.md
index fdab70175a..9cae3145ff 100644
--- a/self-hosted/migration/same-db.md
+++ b/self-hosted/migration/same-db.md
@@ -6,7 +6,7 @@ keywords: [data migration, Postgres]
tags: [import]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Migrate data to TimescaleDB from the same $PG instance
@@ -65,7 +65,7 @@ Migrate your data into $TIMESCALE_DB from within the same database.
-
+
1. Insert data from the old table to the new table.
diff --git a/tutorials/blockchain-query/blockchain-compress.md b/tutorials/blockchain-query/blockchain-compress.md
deleted file mode 100644
index 4270fce016..0000000000
--- a/tutorials/blockchain-query/blockchain-compress.md
+++ /dev/null
@@ -1,99 +0,0 @@
----
-title: Compress your data using hypercore
-excerpt: Compress a sample dataset with Tiger Cloud so you can store the Bitcoin blockchain more efficiently
-products: [cloud, self_hosted, mst]
-keywords: [beginner, crypto, blockchain, Bitcoin, finance, analytics]
-layout_components: [next_prev_large]
-content_group: Query the Bitcoin blockchain
----
-
-import TutorialsHypercoreIntro from "versionContent/_partials/_tutorials-hypercore-intro.mdx"
-
-# Compress your data using $HYPERCORE
-
-
-
-## Optimize your data in the $COLUMNSTORE
-
-To compress the data in the `transactions` table, do the following:
-
-
-
-1. Connect to your $SERVICE_LONG
-
- In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
- You can also connect to your $SERVICE_SHORT using [psql][connect-using-psql].
-
-1. Convert data to the $COLUMNSTORE:
-
- You can do this either automatically or manually:
- - [Automatically convert chunks][add_columnstore_policy] in the $HYPERTABLE to the $COLUMNSTORE at a specific time interval:
-
- ```sql
- CALL add_columnstore_policy('transactions', after => INTERVAL '1d');
- ```
-
- - [Manually convert all chunks][convert_to_columnstore] in the $HYPERTABLE to the $COLUMNSTORE:
-
- ```sql
- DO $$
- DECLARE
- chunk_name TEXT;
- BEGIN
- FOR chunk_name IN (SELECT c FROM show_chunks('transactions') c)
- LOOP
- RAISE NOTICE 'Converting chunk: %', chunk_name; -- Optional: To see progress
- CALL convert_to_columnstore(chunk_name);
- END LOOP;
- RAISE NOTICE 'Conversion to columnar storage complete for all chunks.'; -- Optional: Completion message
- END$$;
- ```
-
-
-
-
-## Take advantage of query speedups
-
-Previously, data in the $COLUMNSTORE was segmented by the `block_id` column value.
-This means fetching data by filtering or grouping on that column is
-more efficient. Ordering is set to time descending. This means that when you run queries
-which try to order data in the same way, you see performance benefits.
-
-
-
-1. Connect to your $SERVICE_LONG
-
- In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
-
-1. Run the following query:
-
- ```sql
- WITH recent_blocks AS (
- SELECT block_id FROM transactions
- WHERE is_coinbase IS TRUE
- ORDER BY time DESC
- LIMIT 5
- )
- SELECT
- t.block_id, count(*) AS transaction_count,
- SUM(weight) AS block_weight,
- SUM(output_total_usd) AS block_value_usd
- FROM transactions t
- INNER JOIN recent_blocks b ON b.block_id = t.block_id
- WHERE is_coinbase IS NOT TRUE
- GROUP BY t.block_id;
- ```
-
- Performance speedup is of two orders of magnitude, around 15 ms when compressed in the $COLUMNSTORE and
- 1 second when decompressed in the $ROWSTORE.
-
-
-
-
-
-[hypercore]: /use-timescale/:currentVersion:/hypercore/
-[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
-[services-portal]: https://console.cloud.timescale.com/dashboard/services
-[connect-using-psql]: /integrations/:currentVersion:/psql#connect-to-your-service
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
-[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
diff --git a/tutorials/blockchain-query/index.md b/tutorials/blockchain-query/index.md
index ade5ca0a6c..9eb1131e87 100644
--- a/tutorials/blockchain-query/index.md
+++ b/tutorials/blockchain-query/index.md
@@ -28,8 +28,6 @@ This tutorial covers:
1. [Ingest data into a $SERVICE_SHORT][blockchain-dataset]: set up and connect to a $SERVICE_LONG, create tables and $HYPERTABLEs, and ingest data.
1. [Query your data][blockchain-query]: obtain information, including finding the most recent transactions on the blockchain, and
gathering information about the transactions using aggregation functions.
-1. [Compress your data using $HYPERCORE][blockchain-compress]: compress data that is no longer needed for highest performance queries, but is still accessed regularly
- for real-time analytics.
When you've completed this tutorial, you can use the same dataset to [Analyze the Bitcoin data][analyze-blockchain],
using $TIMESCALE_DB hyperfunctions.
diff --git a/tutorials/financial-tick-data/financial-tick-compress.md b/tutorials/financial-tick-data/financial-tick-compress.md
deleted file mode 100644
index 45fd4f85b4..0000000000
--- a/tutorials/financial-tick-data/financial-tick-compress.md
+++ /dev/null
@@ -1,104 +0,0 @@
----
-title: Compress your data using hypercore
-excerpt: Compress a sample dataset with Tiger Cloud to store the financial data more efficiently
-products: [cloud, self_hosted, mst]
-keywords: [tutorials, finance, learn]
-tags: [tutorials, beginner]
-layout_components: [next_prev_large]
-content_group: Analyze financial tick data
----
-
-import TutorialsHypercoreIntro from "versionContent/_partials/_tutorials-hypercore-intro.mdx"
-
-# Compress your data using $HYPERCORE
-
-
-
-## Optimize your data in the $COLUMNSTORE
-
-To compress the data in the `crypto_ticks` table, do the following:
-
-
-
-1. Connect to your $SERVICE_LONG
-
- In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
- You can also connect to your $SERVICE_SHORT using [psql][connect-using-psql].
-
-1. Convert data to the $COLUMNSTORE:
-
- You can do this either automatically or manually:
- - [Automatically convert chunks][add_columnstore_policy] in the $HYPERTABLE to the $COLUMNSTORE at a specific time interval:
-
- ```sql
- CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '1d');
- ```
-
- - [Manually convert all chunks][convert_to_columnstore] in the $HYPERTABLE to the $COLUMNSTORE:
-
- ```sql
- CALL convert_to_columnstore(c) from show_chunks('crypto_ticks') c;
- ```
-
-1. Now that you have converted the chunks in your $HYPERTABLE to the $COLUMNSTORE, compare the
- size of the dataset before and after compression:
-
- ```sql
- SELECT
- pg_size_pretty(before_compression_total_bytes) as before,
- pg_size_pretty(after_compression_total_bytes) as after
- FROM hypertable_columnstore_stats('crypto_ticks');
- ```
-
- This shows a significant improvement in data usage:
-
- ```sql
- before | after
- --------+-------
- 694 MB | 75 MB
- (1 row)
- ```
-
-
-
-
-## Take advantage of query speedups
-
-Previously, data in the $COLUMNSTORE was segmented by the `block_id` column value.
-This means fetching data by filtering or grouping on that column is
-more efficient. Ordering is set to time descending. This means that when you run queries
-which try to order data in the same way, you see performance benefits.
-
-
-
-1. Connect to your $SERVICE_LONG
-
- In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
-
-1. Run the following query:
-
- ```sql
- SELECT
- time_bucket('1 day', time) AS bucket,
- symbol,
- FIRST(price, time) AS "open",
- MAX(price) AS high,
- MIN(price) AS low,
- LAST(price, time) AS "close",
- LAST(day_volume, time) AS day_volume
- FROM crypto_ticks
- GROUP BY bucket, symbol;
- ```
-
- Performance speedup is of two orders of magnitude, around 15 ms when compressed in the $COLUMNSTORE and
- 1 second when decompressed in the $ROWSTORE.
-
-
-
-
-[hypercore]: /use-timescale/:currentVersion:/hypercore/
-[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
-[services-portal]: https://console.cloud.timescale.com/dashboard/services
-[connect-using-psql]: /integrations/:currentVersion:/psql#connect-to-your-service
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
-[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
diff --git a/tutorials/financial-tick-data/index.md b/tutorials/financial-tick-data/index.md
index 1428c43066..fdfe30a7d9 100644
--- a/tutorials/financial-tick-data/index.md
+++ b/tutorials/financial-tick-data/index.md
@@ -48,9 +48,6 @@ This tutorial shows you how to ingest real-time time-series data into a $SERVICE
[Twelve Data][twelve-data] into your $TIMESCALE_DB database.
1. [Query your dataset][financial-tick-query]: create candlestick views, query
the aggregated data, and visualize the data in Grafana.
-1. [Compress your data using hypercore][financial-tick-compress]: learn how to store and query
-your financial tick data more efficiently using compression feature of $TIMESCALE_DB.
-
To create candlestick views, query the aggregated data, and visualize the data in Grafana, see the
[ingest real-time websocket data section][advanced-websocket].
diff --git a/tutorials/page-index/page-index.js b/tutorials/page-index/page-index.js
index 4360d04319..00df359bdb 100644
--- a/tutorials/page-index/page-index.js
+++ b/tutorials/page-index/page-index.js
@@ -40,12 +40,6 @@ module.exports = [
href: "beginner-blockchain-query",
excerpt: "Query the Bitcoin blockchain dataset",
},
- {
- title: "Compress your data using hypercore",
- href: "blockchain-compress",
- excerpt:
- "Compress the dataset so you can store the Bitcoin blockchain more efficiently",
- },
],
},
{
@@ -81,12 +75,6 @@ module.exports = [
href: "financial-tick-query",
excerpt: "Query and visualize financial tick data",
},
- {
- title: "Compress your data using hypercore",
- href: "financial-tick-compress",
- excerpt:
- "Compress the dataset so you can store the data more efficiently",
- },
],
},
{
diff --git a/tutorials/real-time-analytics-energy-consumption.md b/tutorials/real-time-analytics-energy-consumption.md
index 308493b2c2..5cc5fe35e6 100644
--- a/tutorials/real-time-analytics-energy-consumption.md
+++ b/tutorials/real-time-analytics-energy-consumption.md
@@ -40,47 +40,6 @@ data optimized for size and speed in the columnstore.
-## Optimize your data for real-time analytics
-
-When $TIMESCALE_DB converts a chunk to the columnstore, it automatically creates a different schema for your
-data. $TIMESCALE_DB creates and uses custom indexes to incorporate the `segmentby` and `orderby` parameters when
-you write to and read from the columstore.
-
-To increase the speed of your analytical queries by a factor of 10 and reduce storage costs by up to 90%, convert data
-to the columnstore:
-
-
-
-1. **Connect to your $SERVICE_LONG**
-
- In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
- You can also connect to your $SERVICE_SHORT using [psql][connect-using-psql].
-
-1. **Add a policy to convert chunks to the columnstore at a specific time interval**
-
- For example, 60 days after the data was added to the table:
- ``` sql
- CALL add_columnstore_policy('metrics', INTERVAL '8 days');
- ```
- See [add_columnstore_policy][add_columnstore_policy].
-
-1. **Faster analytical queries on data in the columnstore**
-
- Now run the analytical query again:
- ```sql
- SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",
- round((last(value, created) - first(value, created)) * 100.) / 100. AS value
- FROM metrics
- WHERE type_id = 5
- GROUP BY 1;
- ```
- On this amount of data, this analytical query on data in the columnstore takes about 250ms.
-
-
-
-Just to hit this one home, by converting cooling data to the columnstore, you have increased the speed of your analytical
-queries by a factor of 10, and reduced storage by up to 90%.
-
## Write fast analytical queries
Aggregation is a way of combining data to get insights from it. Average, sum, and count are all examples of simple
@@ -177,7 +136,6 @@ You have integrated Grafana with a $SERVICE_LONG and made insights based on visu
[alter_table_hypercore]: /api/:currentVersion:/hypercore/alter_table/
[compression_continuous-aggregate]: /api/:currentVersion:/continuous-aggregates/alter_materialized_view/
[informational-views]: /api/:currentVersion:/informational-views/jobs/
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[hypercore_workflow]: /api/:currentVersion:/hypercore/#hypercore-workflow
[alter_job]: /api/:currentVersion:/actions/alter_job/
[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
diff --git a/tutorials/real-time-analytics-transport.md b/tutorials/real-time-analytics-transport.md
index d8430e7990..056b8dc108 100644
--- a/tutorials/real-time-analytics-transport.md
+++ b/tutorials/real-time-analytics-transport.md
@@ -31,40 +31,6 @@ of data optimized for size and speed in the columnstore.
-## Optimize your data for real-time analytics
-
-
-When $TIMESCALE_DB converts a chunk to the columnstore, it automatically creates a different schema for your
-data. $TIMESCALE_DB creates and uses custom indexes to incorporate the `segmentby` and `orderby` parameters when
-you write to and read from the columstore.
-
-To increase the speed of your analytical queries by a factor of 10 and reduce storage costs by up to 90%, convert data
-to the columnstore:
-
-
-
-1. **Connect to your $SERVICE_LONG**
-
- In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
- You can also connect to your $SERVICE_SHORTusing [psql][connect-using-psql].
-
-1. **Add a policy to convert chunks to the columnstore at a specific time interval**
-
- For example, convert data older than 8 days old to the columstore:
- ``` sql
- CALL add_columnstore_policy('rides', INTERVAL '8 days');
- ```
- See [add_columnstore_policy][add_columnstore_policy].
-
- The data you imported for this tutorial is from 2016, it was already added to the $COLUMNSTORE by default. However,
- you get the idea. To see the space savings in action, follow [Try the key $COMPANY features][try-timescale-features].
-
-
-
-Just to hit this one home, by converting cooling data to the columnstore, you have increased the speed of your analytical
-queries by a factor of 10, and reduced storage by up to 90%.
-
-
## Monitor performance over time
@@ -131,7 +97,6 @@ your data.
[alter_table_hypercore]: /api/:currentVersion:/hypercore/alter_table/
[compression_continuous-aggregate]: /api/:currentVersion:/continuous-aggregates/alter_materialized_view/
[informational-views]: /api/:currentVersion:/informational-views/jobs/
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[hypercore_workflow]: /api/:currentVersion:/hypercore/#hypercore-workflow
[alter_job]: /api/:currentVersion:/actions/alter_job/
[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
diff --git a/tutorials/simulate-iot-sensor-data.md b/tutorials/simulate-iot-sensor-data.md
index 14a683373c..c6dd53012d 100644
--- a/tutorials/simulate-iot-sensor-data.md
+++ b/tutorials/simulate-iot-sensor-data.md
@@ -5,8 +5,7 @@ products: [cloud, self_hosted, mst]
keywords: [IoT, simulate]
---
-
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
# Simulate an IoT sensor dataset
@@ -48,11 +47,10 @@ To simulate a dataset, run the following queries:
cpu DOUBLE PRECISION,
FOREIGN KEY (sensor_id) REFERENCES sensors (id)
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
1. **Populate the `sensors` table**:
diff --git a/use-timescale/continuous-aggregates/about-continuous-aggregates.md b/use-timescale/continuous-aggregates/about-continuous-aggregates.md
index 29697a5de8..1bd4fd2519 100644
--- a/use-timescale/continuous-aggregates/about-continuous-aggregates.md
+++ b/use-timescale/continuous-aggregates/about-continuous-aggregates.md
@@ -8,6 +8,7 @@ keywords: [continuous aggregates]
import CaggsFunctionSupport from "versionContent/_partials/_caggs-function-support.mdx";
import CaggsIntro from "versionContent/_partials/_caggs-intro.mdx";
import CaggsTypes from "versionContent/_partials/_caggs-types.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# About continuous aggregates
@@ -75,11 +76,13 @@ CREATE TABLE conditions (
device_id INTEGER,
temperature FLOAT8
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
+
+
+
See the following `JOIN` examples on continuous aggregates:
- `INNER JOIN` on a single equality condition, using the `ON` clause:
diff --git a/use-timescale/continuous-aggregates/create-a-continuous-aggregate.md b/use-timescale/continuous-aggregates/create-a-continuous-aggregate.md
index 3b126dea24..69b5f93c97 100644
--- a/use-timescale/continuous-aggregates/create-a-continuous-aggregate.md
+++ b/use-timescale/continuous-aggregates/create-a-continuous-aggregate.md
@@ -67,7 +67,7 @@ hypertable. Additionally, all functions and their arguments included in
end_offset => INTERVAL '1 day',
schedule_interval => INTERVAL '1 hour');
```
-
+
You can use most $PG aggregate functions in continuous aggregations. To
diff --git a/use-timescale/extensions/postgis.md b/use-timescale/extensions/postgis.md
index 2f620a2e4d..ac7afa866f 100644
--- a/use-timescale/extensions/postgis.md
+++ b/use-timescale/extensions/postgis.md
@@ -6,7 +6,7 @@ keywords: [services, settings, extensions, postgis]
tags: [extensions, postgis]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Analyze geospatial data using postgis
@@ -65,11 +65,10 @@ particular location.
cases INT NOT NULL,
deaths INT NOT NULL
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
1. To support efficient queries, create an index on the `state_id` column:
diff --git a/use-timescale/hypercore/real-time-analytics-in-hypercore.md b/use-timescale/hypercore/real-time-analytics-in-hypercore.md
index e7f728b356..23934cef9f 100644
--- a/use-timescale/hypercore/real-time-analytics-in-hypercore.md
+++ b/use-timescale/hypercore/real-time-analytics-in-hypercore.md
@@ -65,7 +65,6 @@ repeated values, [XOR-based][xor] and [dictionary compression][dictionary] is us
[create-hypertable]: /use-timescale/:currentVersion:/compression/
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[delta]: /use-timescale/:currentVersion:/hypercore/compression-methods/#delta-encoding
[delta-delta]: /use-timescale/:currentVersion:/hypercore/compression-methods/#delta-of-delta-encoding
[simple-8b]: /use-timescale/:currentVersion:/hypercore/compression-methods/#simple-8b
@@ -73,7 +72,6 @@ repeated values, [XOR-based][xor] and [dictionary compression][dictionary] is us
[xor]: /use-timescale/:currentVersion:/hypercore/compression-methods/#xor-based-encoding
[dictionary]: /use-timescale/:currentVersion:/hypercore/compression-methods/#dictionary-compression
[ingest-data]: /getting-started/:currentVersion:/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[run-job]: /api/:currentVersion:/jobs-automation/run_job/
[alter_job]: /api/:currentVersion:/jobs-automation/alter_job/
[informational-views]: /api/:currentVersion:/informational-views/jobs/
diff --git a/use-timescale/hypercore/secondary-indexes.md b/use-timescale/hypercore/secondary-indexes.md
index 3ecec43c0a..f6875263bc 100644
--- a/use-timescale/hypercore/secondary-indexes.md
+++ b/use-timescale/hypercore/secondary-indexes.md
@@ -4,6 +4,8 @@ excerpt: Use segmenting and ordering data in the columnstore to make lookup quer
products: [cloud, mst, self_hosted]
keywords: [hypertable, compression, row-columnar storage, hypercore]
---
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
+
# Improve query and upsert performance
@@ -67,11 +69,12 @@ CREATE TABLE metrics (
device_id INT,
data JSONB
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
+
+
1. **Execute a query on a regular $HYPERTABLE**
diff --git a/use-timescale/hyperfunctions/counter-aggregation.md b/use-timescale/hyperfunctions/counter-aggregation.md
index ea10223474..5b4d65f68d 100644
--- a/use-timescale/hyperfunctions/counter-aggregation.md
+++ b/use-timescale/hyperfunctions/counter-aggregation.md
@@ -4,7 +4,7 @@ excerpt: When collecting data from counters, interruptions usually cause the cou
products: [cloud, mst, self_hosted]
keywords: [hyperfunctions, Toolkit, gauges, counters]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Counter aggregation
@@ -113,11 +113,10 @@ going on in each part.
PRIMARY KEY (measure_id, ts)
) WITH (
tsdb.hypertable,
- tsdb.partition_column='ts',
tsdb.chunk_interval='15 days'
);
```
-
+
1. Create a counter aggregate and the extrapolated delta function:
diff --git a/use-timescale/hypertables/hypertable-crud.md b/use-timescale/hypertables/hypertable-crud.md
index e116dbc429..8bb0bd826e 100644
--- a/use-timescale/hypertables/hypertable-crud.md
+++ b/use-timescale/hypertables/hypertable-crud.md
@@ -6,8 +6,8 @@ keywords: [hypertables, create]
---
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
import HypercoreDirectCompress from "versionContent/_partials/_hypercore-direct-compress.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Optimize time-series data in hypertables
@@ -24,8 +24,8 @@ time. Typically, you partition hypertables on columns that hold time values.
## Create a hypertable
Create a [$HYPERTABLE][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
-For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will use
-most often to filter your data:
+For [efficient queries][secondary-indexes], remember to `segmentby` the column you will use most often to filter your
+data:
```sql
CREATE TABLE conditions (
@@ -36,13 +36,13 @@ CREATE TABLE conditions (
humidity DOUBLE PRECISION NULL
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.segmentby = 'device',
tsdb.orderby = 'time DESC'
);
```
-
+
+
To convert an existing table with data in it, call `create_hypertable` on that table with
[`migrate_data` to `true`][api-create-hypertable-arguments]. However, if you have a lot of data, this may take a long time.
@@ -51,23 +51,6 @@ To convert an existing table with data in it, call `create_hypertable` on that t
-## Optimize cooling data in the $COLUMNSTORE
-
-As the data cools and becomes more suited for analytics, [add a columnstore policy][add_columnstore_policy] so your data
-is automatically converted to the $COLUMNSTORE after a specific time interval. This columnar format enables fast
-scanning and aggregation, optimizing performance for analytical workloads while also saving significant storage space.
-In the $COLUMNSTORE conversion, $HYPERTABLE chunks are compressed by up to 98%, and organized for efficient,
-large-scale queries. This columnar format enables fast scanning and aggregation, optimizing performance for analytical
-workloads.
-
-To optimize your data, add a $COLUMNSTORE policy:
-
-```sql
-CALL add_columnstore_policy('conditions', after => INTERVAL '1d');
-```
-
-You can also manually [convert chunks][convert_to_columnstore] in a $HYPERTABLE to the $COLUMNSTORE.
-
## Alter a hypertable
You can alter a hypertable, for example to add a column, by using the $PG
@@ -118,7 +101,6 @@ All data chunks belonging to the hypertable are deleted.
[postgres-altertable]: https://www.postgresql.org/docs/current/sql-altertable.html
[hypertable-create-table]: /api/:currentVersion:/hypertable/create_table/
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[install]: /getting-started/:currentVersion:/
[postgres-createtable]: https://www.postgresql.org/docs/current/sql-createtable.html
[postgresql-timestamp]: https://wiki.postgresql.org/wiki/Don't_Do_This#Don.27t_use_timestamp_.28without_time_zone.29
@@ -129,7 +111,5 @@ All data chunks belonging to the hypertable are deleted.
[hypertable-create-table]: /api/:currentVersion:/hypertable/create_table/
[hypercore]: /use-timescale/:currentVersion:/hypercore/
[secondary-indexes]: /use-timescale/:currentVersion:/hypercore/secondary-indexes/
-[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
-[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
[timestamps-best-practice]: https://wiki.postgresql.org/wiki/Don't_Do_This#Don.27t_use_timestamp_.28without_time_zone.29
[uuidv7_functions]: /api/:currentVersion:/uuid-functions/
\ No newline at end of file
diff --git a/use-timescale/hypertables/hypertables-and-unique-indexes.md b/use-timescale/hypertables/hypertables-and-unique-indexes.md
index 218922a82f..d69200043a 100644
--- a/use-timescale/hypertables/hypertables-and-unique-indexes.md
+++ b/use-timescale/hypertables/hypertables-and-unique-indexes.md
@@ -5,7 +5,7 @@ products: [cloud, mst, self_hosted]
keywords: [hypertables, unique indexes, primary keys]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Enforce constraints with unique indexes
@@ -46,12 +46,11 @@ To create a unique index on a $HYPERTABLE:
value FLOAT
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.segmentby = 'device_id',
tsdb.orderby = 'time DESC'
);
```
-
+
1. **Create a unique index on the $HYPERTABLE**
diff --git a/use-timescale/hypertables/improve-query-performance.md b/use-timescale/hypertables/improve-query-performance.md
index 8207204f8f..693e476024 100644
--- a/use-timescale/hypertables/improve-query-performance.md
+++ b/use-timescale/hypertables/improve-query-performance.md
@@ -5,7 +5,6 @@ products: [cloud, mst, self_hosted]
keywords: [hypertables, indexes, chunks]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
import ChunkInterval from "versionContent/_partials/_chunk-interval.mdx";
import EarlyAccess2171 from "versionContent/_partials/_early_access_2_17_1.mdx";
@@ -43,13 +42,10 @@ Adjusting your hypertable chunk interval can improve performance in your databas
humidity DOUBLE PRECISION NULL
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.chunk_interval='1 day'
);
```
-
-
1. **Check current setting for chunk intervals**
Query the $TIMESCALE_DB catalog for a $HYPERTABLE. For example:
diff --git a/use-timescale/hypertables/index.md b/use-timescale/hypertables/index.md
index 306d5d3ae2..f7c0f8b275 100644
--- a/use-timescale/hypertables/index.md
+++ b/use-timescale/hypertables/index.md
@@ -100,7 +100,6 @@ For example:
)
WITH(
timescaledb.hypertable,
- timescaledb.partition_column='time',
timescaledb.chunk_interval='1 day'
);
```
diff --git a/use-timescale/query-data/advanced-analytic-queries.md b/use-timescale/query-data/advanced-analytic-queries.md
index 4e837d3ffd..1995aeab34 100644
--- a/use-timescale/query-data/advanced-analytic-queries.md
+++ b/use-timescale/query-data/advanced-analytic-queries.md
@@ -5,7 +5,7 @@ products: [cloud, mst, self_hosted]
keywords: [queries, hyperfunctions, analytics]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# Perform advanced analytical queries
@@ -353,12 +353,11 @@ CREATE TABLE location (
latitude FLOAT,
longitude FLOAT
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
You can use the first table, which gives a distinct set of vehicles, to
perform a `LATERAL JOIN` against the location table:
diff --git a/use-timescale/schema-management/about-constraints.md b/use-timescale/schema-management/about-constraints.md
index 2cd5568419..d383633f34 100644
--- a/use-timescale/schema-management/about-constraints.md
+++ b/use-timescale/schema-management/about-constraints.md
@@ -5,7 +5,7 @@ products: [cloud, mst, self_hosted]
keywords: [schemas, constraints]
---
-import OldCreateHypertable from "versionContent/_partials/_old-api-create-hypertable.mdx";
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
# About constraints
@@ -34,12 +34,11 @@ CREATE TABLE conditions (
location INTEGER REFERENCES locations (id),
PRIMARY KEY(time, device_id)
) WITH (
- tsdb.hypertable,
- tsdb.partition_column='time'
+ tsdb.hypertable
);
```
-
+
This example also references values in another `locations` table using a foreign
key constraint.
diff --git a/use-timescale/schema-management/indexing.md b/use-timescale/schema-management/indexing.md
index d1c7fd0a0a..3fca99ae8a 100644
--- a/use-timescale/schema-management/indexing.md
+++ b/use-timescale/schema-management/indexing.md
@@ -5,6 +5,8 @@ products: [cloud, mst, self_hosted]
keywords: [hypertables, indexes]
---
+import CreateHypertablePolicyNote from "versionContent/_partials/_create-hypertable-columnstore-policy-note.mdx";
+
# Indexing data
You can use an index on your database to speed up read operations. You can
@@ -56,13 +58,11 @@ CREATE TABLE conditions (
humidity DOUBLE PRECISION NULL
) WITH (
tsdb.hypertable,
- tsdb.partition_column='time',
tsdb.create_default_indexes=false
);
```
-
-
+
## Best practices for indexing