
Track and analyze your local LLM usage across coding agents




📖 Documentation · ⚡ Quick Start · 📊 Examples · 🤝 Contributing
Aggregate token usage and costs from your local coding agent sessions. Supports pi, codex, Gemini CLI, Droid CLI, and OpenCode with zero configuration required.
- Zero-Config Discovery — Automatically finds
.pi,.codex,.gemini,.factory, and OpenCode session data - LiteLLM Pricing — Real-time pricing sync with offline caching support
- Flexible Reports — Daily, weekly, and monthly aggregations
- Efficiency Reports — Correlate cost/tokens with repository commit outcomes
- Multiple Outputs — Terminal tables, JSON, or Markdown
- Smart Filtering — By source, provider, model, and date ranges
# Install globally
npm install -g llm-usage-metrics
# Or run without installing
npx llm-usage-metrics@latest daily
# Generate your first report
llm-usage daily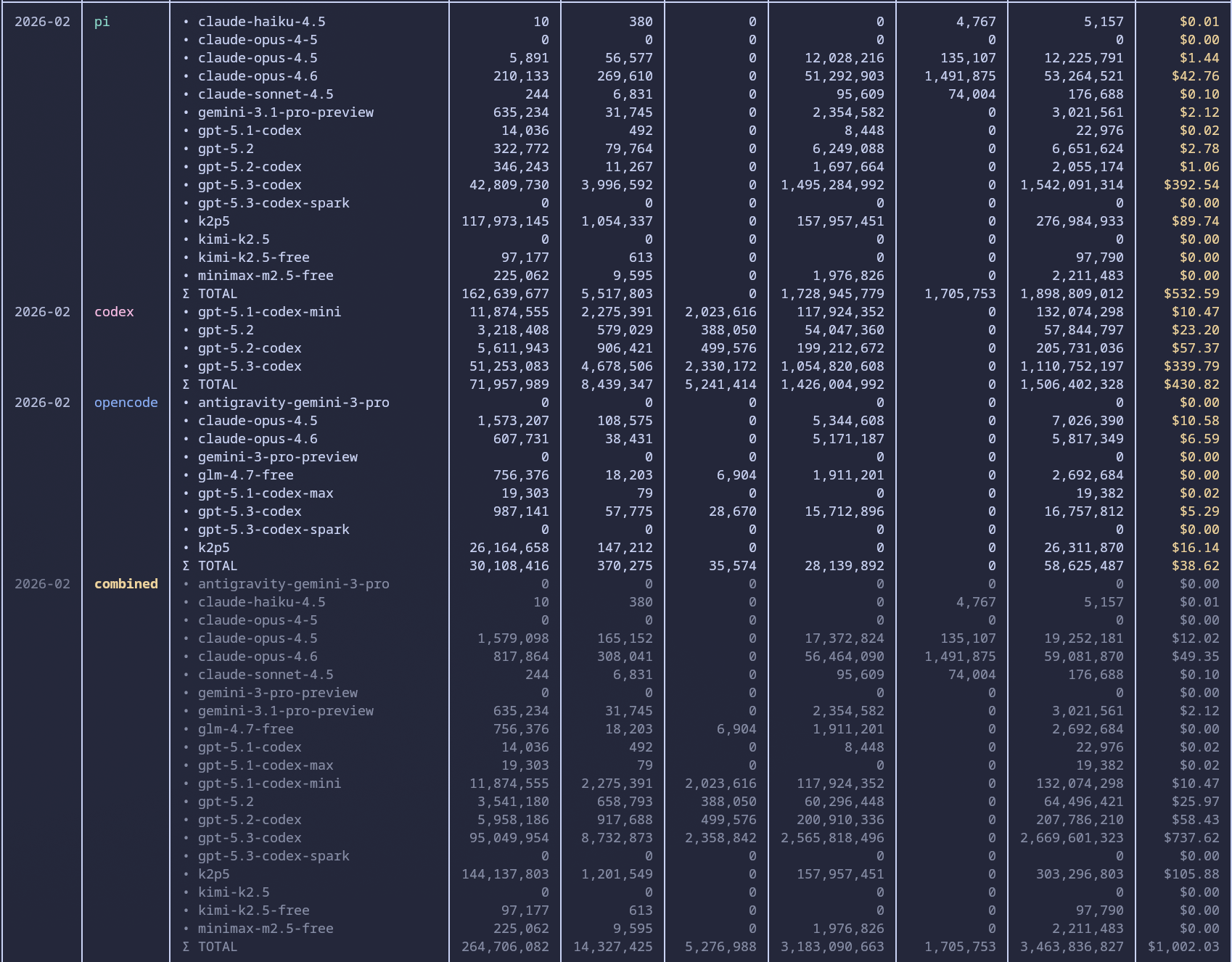
| Source | Pattern | Discovery |
|---|---|---|
| pi | ~/.pi/agent/sessions/**/*.jsonl |
Automatic |
| codex | ~/.codex/sessions/**/*.jsonl |
Automatic |
| Gemini CLI | ~/.gemini/tmp/*/chats/*.json |
Automatic |
| Droid CLI | ~/.factory/sessions/**/*.settings.json |
Automatic |
| OpenCode | ~/.opencode/opencode.db |
Auto or explicit --opencode-db |
OpenCode source support requires Node.js 24+ runtime with built-in node:sqlite.
For droid, Input, Output, Reasoning, Cache Read, and Cache Write come directly from session files, and totalTokens is billable raw tokens (Input + Output + Cache Read + Cache Write, excluding Reasoning). Factory dashboard totals may differ because Factory applies standard-token normalization/multipliers.
# Daily report (default terminal table)
llm-usage daily
# Weekly with timezone
llm-usage weekly --timezone Europe/Paris
# Monthly date range
llm-usage monthly --since 2026-01-01 --until 2026-01-31# JSON for pipelines
llm-usage daily --json
# Markdown for documentation
llm-usage daily --markdown
# Detailed per-model breakdown
llm-usage monthly --per-model-columns# Daily efficiency in current repository
llm-usage efficiency daily
# Weekly efficiency for a specific repository path
llm-usage efficiency weekly --repo-dir /path/to/repo
# Include merge commits and export JSON
llm-usage efficiency monthly --include-merge-commits --jsonEfficiency reports are repo-attributed: usage events are mapped to a Git repository root using source metadata (cwd/path info), and only events attributed to the selected repo are included in efficiency totals.
Commits,+Lines,-Lines,ΔLinescome from local Git shortstat outcomes (for your configured Git author).Input,Output,Reasoning,Cache Read,Cache Write,Total, andCostcome from repo-attributed usage events.All Tokens/CommitusesTotal / Commitsand includes cache read/write tokens.Non-Cache/Commituses(Input + Output + Reasoning) / Commitsand excludes cache read/write tokens.$/CommitusesCost / Commits.$/1k LinesusesCost / (ΔLines / 1000).Commits/$usesCommits / Cost(shown only whenCost > 0).
Efficiency period rows are emitted only when both Git outcomes and repo-attributed usage signal exist for that period.
When a denominator is zero, derived values in emitted rows render as -.
When pricing is incomplete, terminal/markdown output prefixes affected USD metrics with ~.
For source-by-source comparisons, run the same report per source:
llm-usage efficiency monthly --repo-dir /path/to/repo --source pi
llm-usage efficiency monthly --repo-dir /path/to/repo --source codex
llm-usage efficiency monthly --repo-dir /path/to/repo --source gemini
llm-usage efficiency monthly --repo-dir /path/to/repo --source droid
llm-usage efficiency monthly --repo-dir /path/to/repo --source opencodeNote: usage filters (--source, --provider, --model, --pi-dir, --codex-dir, --gemini-dir, --droid-dir, --opencode-db, --source-dir) also constrain commit attribution: only commit days with matching repo-attributed usage events are counted.
# By source
llm-usage monthly --source pi,codex,gemini,droid
# By provider
llm-usage monthly --provider openai
# By model
llm-usage monthly --model claude
# Combined filters
llm-usage monthly --source opencode --provider openai --model gpt-4.1# Custom directories
llm-usage daily --source-dir pi=/path/to/pi --source-dir codex=/path/to/codex --source-dir gemini=/path/to/.gemini --source-dir droid=/path/to/.factory/sessions
# Explicit Gemini/Droid/OpenCode paths
llm-usage daily --gemini-dir /path/to/.gemini
llm-usage daily --droid-dir /path/to/.factory/sessions
llm-usage daily --opencode-db /path/to/opencode.db# Use cached pricing only
llm-usage monthly --pricing-offline
# Continue even if pricing fetch fails
llm-usage monthly --ignore-pricing-failuresBenchmarked on February 27, 2026 on a local production machine:
- OS: CachyOS (Linux 6.19.2-2-cachyos)
- CPU: Intel Core Ultra 9 185H (22 logical CPUs)
- RAM: 62 GiB
- Storage: NVMe SSD
Compared scenarios:
# direct source-to-source parity (openai provider)
ccusage-codex monthly
llm-usage monthly --provider openai --source codex
# multi-source comparison for one provider (openai)
ccusage-codex monthly
llm-usage monthly --provider openai --source pi,codex,gemini,opencodeTimed benchmark summary (5 runs per scenario).
Direct source-to-source parity (--source codex):
| Tool | Cache mode | Median (s) | Mean (s) |
|---|---|---|---|
ccusage-codex monthly |
no cache | 16.785 | 17.288 |
ccusage-codex monthly --offline |
with cache | 16.995 | 17.594 |
llm-usage monthly --provider openai --source codex |
no cache | 3.651 | 3.760 |
llm-usage monthly --provider openai --source codex --pricing-offline |
with cache | 0.746 | 0.724 |
Speedups (median): 4.60x faster cold, 22.78x faster cached.
Multi-source OpenAI (--source pi,codex,gemini,opencode):
| Tool | Cache mode | Median (s) | Mean (s) |
|---|---|---|---|
ccusage-codex monthly |
no cache | 17.297 | 17.463 |
ccusage-codex monthly --offline |
with cache | 16.698 | 16.745 |
llm-usage monthly --provider openai --source pi,codex,gemini,opencode |
no cache | 4.767 | 4.864 |
llm-usage monthly --provider openai --source pi,codex,gemini,opencode --pricing-offline |
with cache | 0.941 | 0.951 |
Speedups (median): 3.63x faster cold, 17.75x faster cached.
Full methodology, cache-mode definition, and scope caveats are documented in the Astro docs: Benchmarks.
Re-run direct parity benchmark locally:
pnpm run perf:production-benchmark -- --runs 5 --llm-source codexRe-run multi-source OpenAI benchmark locally:
pnpm run perf:production-benchmark -- --runs 5 --llm-source pi,codex,gemini,opencodeGenerate machine-readable artifacts:
pnpm run perf:production-benchmark -- \
--runs 5 \
--llm-source codex \
--json-output ./tmp/production-benchmark-openai-codex.json \
--markdown-output ./tmp/production-benchmark-openai-codex.md
pnpm run perf:production-benchmark -- \
--runs 5 \
--llm-source pi,codex,gemini,opencode \
--json-output ./tmp/production-benchmark-openai-multi-source.json \
--markdown-output ./tmp/production-benchmark-openai-multi-source.md| Variable | Description |
|---|---|
LLM_USAGE_SKIP_UPDATE_CHECK |
Skip update check (1) |
LLM_USAGE_PRICING_CACHE_TTL_MS |
Pricing cache duration |
LLM_USAGE_PARSE_MAX_PARALLEL |
Max parallel file parses (1-64) |
LLM_USAGE_PARSE_CACHE_ENABLED |
Enable parse cache (1/0) |
Parse cache is source-sharded on disk (parse-file-cache.<source>.json) so source-scoped runs avoid loading unrelated cache blobs.
See full environment variable reference in the documentation.
The CLI performs lightweight update checks with smart defaults:
- 1-hour cache TTL
- Skipped for
--help,--version, andnpxruns - Prompts only in interactive TTY sessions
Disable with:
LLM_USAGE_SKIP_UPDATE_CHECK=1 llm-usage daily# Install dependencies
pnpm install
# Run quality checks
pnpm run lint
pnpm run typecheck
pnpm run test
pnpm run format:check
# Build
pnpm run build
# Run locally
pnpm cli daily- Getting Started — Installation and first steps
- CLI Reference — Complete command reference
- Efficiency — Efficiency report semantics and interpretation
- Data Sources — Source configuration
- Configuration — Environment variables
- Benchmarks — Production benchmark methodology and results
- Architecture — Technical overview
Contributions are welcome! See CONTRIBUTING.md for guidelines.
The codebase is structured to add more sources through the SourceAdapter pattern.
MIT © Abdeslam Yagmar