Database Management Systems: Project-> My Work
This is the Schema of the IMDB Database
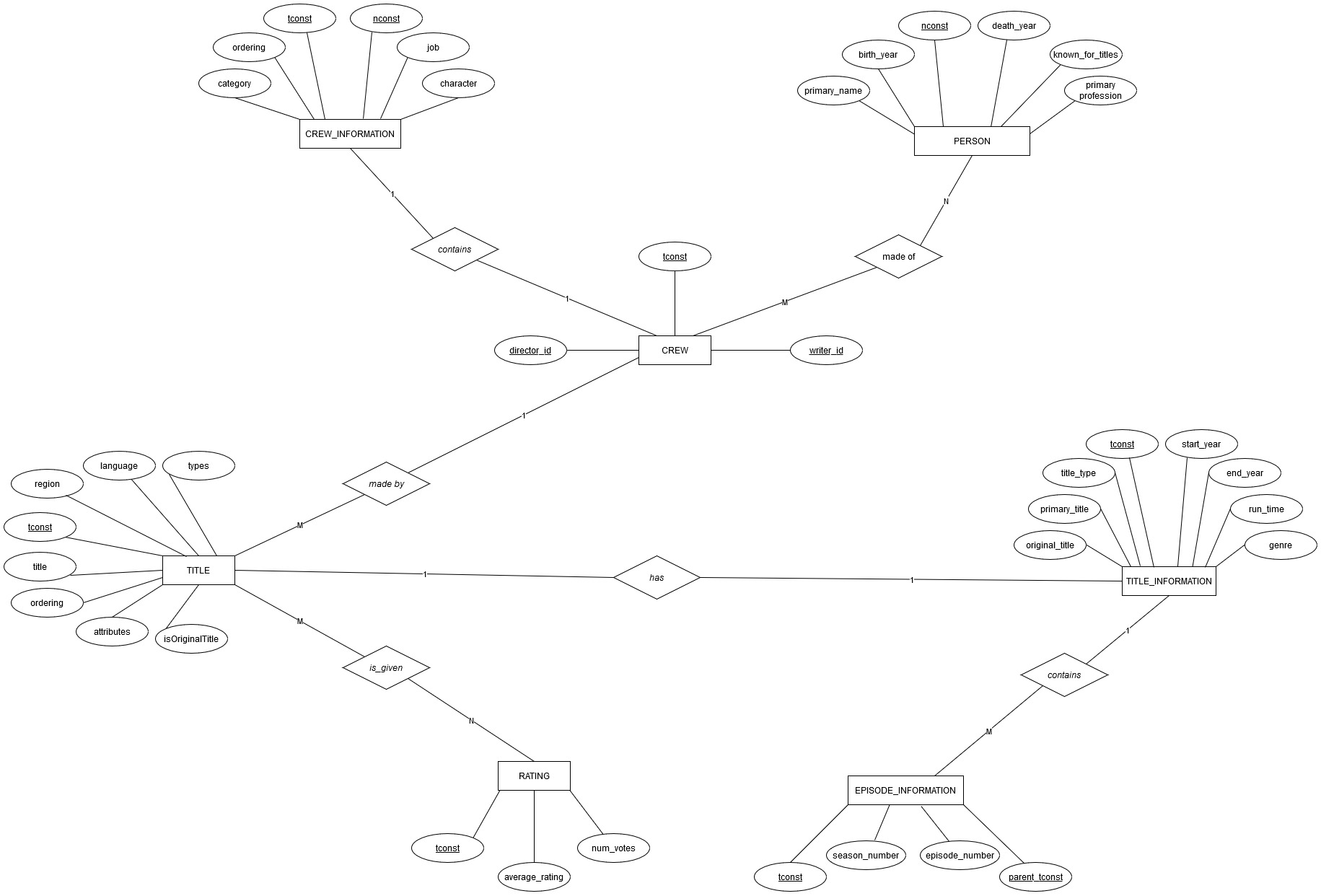
The relational schemas that we have constructed are represented in the form R(A1 : D1,….,An : Dn) are as follows:
• Title( tconst: string, ordering: integer, title: string, region: string, language: string, types: array, attributes: array, isOriginalTitle: boolean)
• Title_information( tconst: string, title_type: string, primary_title: string, original_title: string, isAdult: boolean, Start_year: time, End_year: time, Run_time: integer, genre: string)
• Crew_id( tconst: string, director_id: string, writer_id: string)
• Episode_information( tconst: string, parent_tconst: string, season_number: integer, episode_number: integer)
• Crew_information(tconst: string, ordering: integer, nconst: integer, category: string, job: string, character: string )
• Ratings( tconst: string, average_rating: float, num_votes: integer)
• Personal_information( nconst:string, primary_name: string, birth_year: time, death_year: time, primary_profession: string, known_for_titles: string)
My work was to clean the IMDB dataset which was more than a 39 million entries long and to design complex SQL queries as stated in the project description. I used Pandas with Python to clean the dataset and MYSQL to design complex SQL queries.